publications
...and preprints
Also see Google Scholar and Semantic Scholar.
2026
- ICMLAtharva Kulkarni , Jacob Mitchell Springer , Arjun Subramonian , and Swabha SwayamdiptaProc. of ICML, 2026
Geometric properties of Transformer weights, particularly the unembedding matrix, have been widely useful in language model interpretability research. Yet, their utility for estimating downstream performance remains unclear. In this work, we systematically investigate the relationship between model performance and the unembedding matrix geometry, particularly its effective rank. Our experiments, involving a suite of 108 OLMo-style language models trained under controlled variation, reveal several key findings. While the best-performing models often exhibit a high effective rank, this trend is not universal across tasks and training setups. Contrary to prior work, we find that low effective rank does not cause late-stage performance degradation in small models, but instead co-occurs with it; we find adversarial cases where low-rank models do not exhibit saturation. Moreover, we show that effective rank is strongly influenced by pre-training hyperparameters, such as batch size and weight decay, which in-turn affect the model’s performance. Lastly, extending our analysis to other geometric metrics and final-layer representation, we find that these metrics are largely aligned, but none can reliably predict downstream performance. Overall, our findings suggest that the model’s geometry, as captured by existing metrics, primarily reflects training choices rather than performance.
- ACL
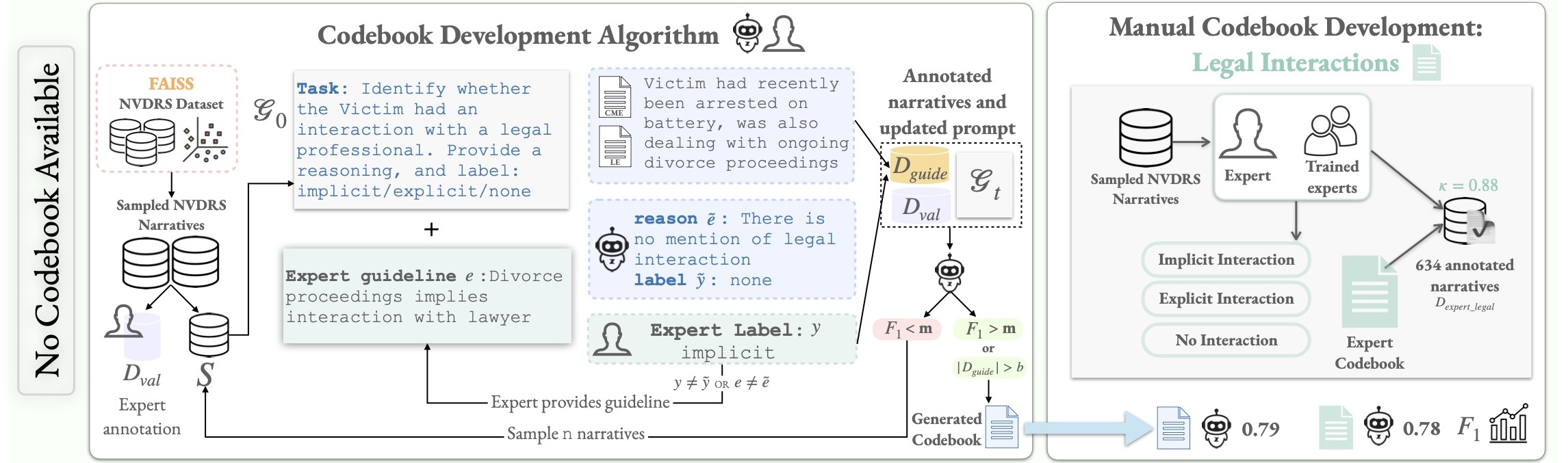 Jaspreet Ranjit , Hyundong J. Cho , Claire J. Smerdon , Yoonsoo Nam , Myles Phung , Jonathan May , John R. Blosnich , and Swabha SwayamdiptaProc. of ACL / NeurIPS Workshop on GenAI for Health / EAAMO, 2026
Jaspreet Ranjit , Hyundong J. Cho , Claire J. Smerdon , Yoonsoo Nam , Myles Phung , Jonathan May , John R. Blosnich , and Swabha SwayamdiptaProc. of ACL / NeurIPS Workshop on GenAI for Health / EAAMO, 2026The National Violent Death Reporting System (NVDRS) documents information about suicides in the United States, including free text narratives (e.g., circumstances surrounding a suicide). In a demanding public health data pipeline, annotators manually extract structured information from death investigation records following extensive guidelines developed painstakingly by experts. In this work, we facilitate data-driven insights from the NVDRS data to support the development of novel suicide interventions by investigating the value of language models (LMs) as efficient assistants to these (a) data annotators and (b) experts. We find that LM predictions match existing data annotations about 85% of the time across 50 NVDRS variables. In the cases where the LM disagrees with existing annotations, expert review reveals that LM assistants can surface annotation discrepancies 38% of the time. Finally, we introduce a human-in-the-loop algorithm to assist experts in efficiently building and refining guidelines for annotating new variables by allowing them to focus only on providing feedback for incorrect LM predictions. We apply our algorithm to a real-world case study for a new variable that characterizes victim interactions with lawyers and demonstrate that it achieves comparable annotation quality with a laborious manual approach. Our findings provide evidence that LMs can serve as effective assistants to public health researchers who handle sensitive data in high-stakes scenarios.
- ACLKeyu He , Tejas Srinivasan , Brihi Joshi , Xiang Ren , Jesse Thomason , and Swabha SwayamdiptaProc. of ACL, 2026
When people query Vision-Language Models (VLMs) but cannot see the accompanying visual context (e.g. for blind and low-vision users), augmenting VLM predictions with natural language explanations can signal which model predictions are reliable. However, prior work has found that explanations can easily convince users that inaccurate VLM predictions are correct. To remedy undesirable overreliance on VLM predictions, we propose evaluating two complementary qualities of VLM-generated explanations via two quality scoring functions. We propose Visual Fidelity, which captures how faithful an explanation is to the visual context, and Contrastiveness, which captures how well the explanation identifies visual details that distinguish the model’s prediction from plausible alternatives. On the A-OKVQA and VizWiz tasks, these quality scoring functions are better calibrated with model correctness than existing explanation qualities. We conduct a user study in which participants have to decide whether a VLM prediction is accurate without viewing its visual context. We observe that showing our quality scores alongside VLM explanations improves participants’ accuracy at predicting VLM correctness by 11.1%, including a 15.4% reduction in the rate of falsely believing incorrect predictions. These findings highlight the utility of explanation quality scores in fostering appropriate reliance on VLM predictions.
- Guy Kaplan , Zorik Gekhman , Zhen Zhu , Lotem Rozner , Yuval Reif , Swabha Swayamdipta, Derek Hoiem , and Roy SchwartzUnder Submission, 2026
Large language models are prone to hallucinating factually incorrect statements. A key source of these errors is exposure to new factual information through supervised fine-tuning (SFT), which can increase hallucinations w.r.t. knowledge acquired during pre-training. In this work, we explore whether SFT-induced hallucinations can be mitigated using established tools from the continual learning literature, since they arise as a by-product of knowledge degradation during training. We propose a self-distillation-based SFT method that facilitates effective factual learning while minimizing hallucinations w.r.t. pre-existing knowledge by regularizing output-distribution drift. We also show that, in settings where new knowledge acquisition is unnecessary, suppressing factual plasticity by freezing parameter groups, can preserve task performance while reducing hallucinations. Lastly, we investigate the mechanism behind SFT-induced hallucinations through three hypotheses: capacity limitations, behavior cloning, and localized interference. Our experiments show that a main driver is interference among overlapping semantic representations, and that self-distillation succeeds by mitigating this interference.
- Proc. of FAccTThe Ninth Annual ACM Conference on Fairness, Accountability, and Transparency, 2026
Language models (LMs) can exhibit systematic biases against speakers based on variations in their dialects, even in the absence of a dialect label, a behavior known as covert dialect bias. In this work, we quantify covert dialect bias in online discourse by evaluating how LMs associate stereotypical traits (derived from social psychology research on racial bias) with intent-equivalent tweets in Standard American English (SAE) and African-American Vernacular English (AAVE). While prior work shows that LMs associate more negative stereotypes with AAVE when evaluating tweets in isolation, we are surprised to find that this bias is significantly exacerbated when SAE / AAVE tweet pairs are compared side by side, a setting that more closely reflects high-impact decision making contexts in which models are used to rank candidates. The bias only worsens when dialect labels are explicitly specified. This is striking, given the extensive efforts from commercial developers to mitigate bias in their LMs. Encouragingly, we show that counterfactual fairness finetuning can mitigate covert dialect bias for some stereotypical traits, reducing average disparities when evaluating tweets in isolation, however, these improvements do not consistently hold across traits when evaluating SAE / AAVE tweets side by side. Our findings show that existing evaluation settings for covert dialect bias may underestimate its severity, specifically in contrastive settings. Additionally, overt dialect bias remains pronounced even after safety aligned finetuning, indicating that it remains an unresolved problem, and motivates the need for more robust evaluation and mitigation frameworks.
- Harshita Diddee , Gregory Yauney , Swabha Swayamdipta, and Daphne IppolitoUnder Submission, 2026
Do language model benchmarks actually measure what practitioners intend them to? High-level metadata is too coarse to convey the granular reality of benchmarks: a "poetry" benchmark may never test for haikus, while "instruction-following" benchmarks will often test for an arbitrary mix of skills. This opacity makes verifying alignment with practitioner goals a laborious process, risking an illusion of competence even when models fail on untested facets of user interests. We introduce BenchBrowser, a retriever that surfaces evaluation items relevant to natural language use cases over 20 benchmark suites. Validated by a human study confirming high retrieval precision, BenchBrowser generates evidence to help practitioners diagnose low content validity (narrow coverage of a capability’s facets) and low convergent validity (lack of stable rankings when measuring the same capability). BenchBrowser, thus, helps quantify a critical gap between practitioner intent and what benchmarks actually test.
- Matthew Finlayson , Xiang Ren , and Swabha SwayamdiptaProc. of ICLR, 2026
The ubiquity of closed-weight language models with public-facing APIs has generated interest in forensic methods, both for extracting hidden model details (e.g., parameters) and for identifying models by their outputs. One successful approach to these goals has been to exploit the geometric constraints imposed by the language model architecture and parameters. In this work, we show that a lesser-known geometric constraint–namely, that language model outputs lie on the surface of a high-dimensional ellipse–functions as a signature for the model and can be used to identify the source model of a given output. This ellipse signature has unique properties that distinguish it from existing model-output association methods like language model fingerprints. In particular, the signature is hard to forge: without direct access to model parameters, it is practically infeasible to produce log-probabilities (logprobs) on the ellipse. Secondly, the signature is naturally occurring, since all language models have these elliptical constraints. Thirdly, the signature is self-contained, in that it is detectable without access to the model inputs or the full weights. Finally, the signature is compact and redundant, as it is independently detectable in each logprob output from the model. We evaluate a novel technique for extracting the ellipse from small models and discuss the practical hurdles that make it infeasible for production-scale models. Finally, we use ellipse signatures to propose a protocol for language model output verification, analogous to cryptographic symmetric-key message authentication systems.
- Gregory Yauney , Shahzaib Saqib Warraich , and Swabha SwayamdiptaProc. of ICLR, 2026
Micro-benchmarking offers a solution to the often prohibitive time and cost of language model development: evaluate on a very small subset of existing benchmarks. Can these micro-benchmarks, however, rank models as consistently as the full benchmarks they replace? And can they rank models more consistently than selecting a random subset of data points? In many scenarios, we find that the answer is no. We introduce a meta-evaluation measure for micro-benchmarking which investigates how well a micro-benchmark can rank two models as a function of their performance difference on the full benchmark. This approach can determine which model pairs can be ranked correctly by a micro-benchmark, allowing for a finer-grained analysis of the trade-off between micro-benchmark size and reliability. Prior work has suggested selecting as few as 10 examples; we find that no micro-benchmarking method can consistently rank model pairs 3.5 points of accuracy apart on MMLU-Pro or 4 points apart on BIG-bench Hard. In order to consistently rank model pairs with relatively similar performances, we show that often as many as 250 examples must be selected, at which point random sampling is competitive with existing micro-benchmarking methods. When comparing only 8B instruction-tuned models on MMLU-Pro micro-benchmarks with 25 examples, we find that more than half of pairwise comparisons are not likely to be preserved. Our work provides actionable guidance for both micro-benchmark users and developers in navigating the trade-off between evaluation efficiency and reliability.
- CHIJaspreet Ranjit , Ke Zhou , Swabha Swayamdipta, and Quercia DanieleProc. of CHI, 2026
Prior work has mapped which workplace tasks are exposed to AI, but less is known about whether workers perceive these tasks as meaningful or as busywork. We examined: (1) which dimensions of meaningful work do workers associate with tasks exposed to AI; and (2) how do the traits of existing AI systems compare to the traits workers want. We surveyed workers and developers on a representative sample of 171 tasks and use language models to scale ratings to 10,131 tasks across all U.S. computer-assisted tasks. Worryingly, we find that tasks that workers associate with a sense of agency or happiness may be disproportionately exposed to AI. We also document HCI design gaps: developers report emphasizing politeness, strictness, and imagination in system design; by contrast, workers prefer systems that are straightforward, tolerant, and practical. To address these gaps, we call for AI whose design explicitly centers meaningful work and worker needs, proposing a five-part research agenda.
- Saleh Afroogh , Seyd Ishtiaque Ahmed , Petra Ahrweiler , David Alvarez-Melis , Mansur Maturidi Arief , Emilia Barakova , Falco J. Bargagli-Stoffi , Erdem Biyik , Hanjie Chen , and 40 more authorsUnder Submission, 2026
This study provides a cross-disciplinary examination of Explainable Artificial Intelligence (XAI) approaches-focusing on deep neural networks (DNNs) and large language models (LLMs)-and identifies empirical and conceptual limitations in current XAI. We discuss critical symptoms that stem from deeper root causes (i.e., two paradoxes, two conceptual confusions, and five false assumptions). These fundamental problems within the current XAI research field reveal three insights: experimentally, XAI exhibits significant flaws; conceptually, it is paradoxical; and pragmatically, further attempts to reform the paradoxical XAI might exacerbate its confusion-demanding fundamental shifts and new research directions. To move beyond XAI’s limitations, we propose a four-pronged synthesized paradigm shift toward reliable and certified AI development. These four components include: verification-focused Interactive AI (IAI) to establish scientific community protocols for certifying AI system performance rather than attempting post-hoc explanations, AI Epistemology for rigorous scientific foundations, User-Sensible AI to create context-aware systems tailored to specific user communities, and Model-Centered Interpretability for faithful technical analysis-together offering comprehensive post-XAI research directions.
- Yue Huang , Chujie Gao , Siyuan Wu , Haoran Wang , Xiangqi Wang , Yujun Zhou , Yanbo Wang , Jiayi Ye , Jiawen Shi , and 57 more authorsICLR, 2026
Generative Foundation Models (GenFMs) have emerged as transformative tools. However, their widespread adoption raises critical concerns regarding trustworthiness across dimensions. This paper presents a comprehensive framework to address these challenges through three key contributions. First, we systematically review global AI governance laws and policies from governments and regulatory bodies, as well as industry practices and standards. Based on this analysis, we propose a set of guiding principles for GenFMs, developed through extensive multidisciplinary collaboration that integrates technical, ethical, legal, and societal perspectives. Second, we introduce TrustGen, the first dynamic benchmarking platform designed to evaluate trustworthiness across multiple dimensions and model types, including text-to-image, large language, and vision-language models. TrustGen leverages modular components–metadata curation, test case generation, and contextual variation–to enable adaptive and iterative assessments, overcoming the limitations of static evaluation methods. Using TrustGen, we reveal significant progress in trustworthiness while identifying persistent challenges. Finally, we provide an in-depth discussion of the challenges and future directions for trustworthy GenFMs, which reveals the complex, evolving nature of trustworthiness, highlighting the nuanced trade-offs between utility and trustworthiness, and consideration for various downstream applications, identifying persistent challenges and providing a strategic roadmap for future research. This work establishes a holistic framework for advancing trustworthiness in GenAI, paving the way for safer and more responsible integration of GenFMs into critical applications. To facilitate advancement in the community, we release the toolkit for dynamic evaluation.



2025
- NeurIPS
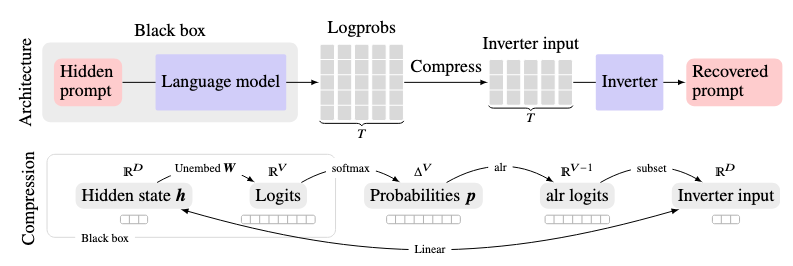 Murtaza Nazir , Matthew Finlayson , John X. Morris , Xiang Ren , and Swabha SwayamdiptaProc. of NeurIPS, 2025
Murtaza Nazir , Matthew Finlayson , John X. Morris , Xiang Ren , and Swabha SwayamdiptaProc. of NeurIPS, 2025Language model inversion seeks to recover hidden prompts using only language model outputs. This capability has implications for security and accountability in language model deployments, such as leaking private information from an API-protected language model’s system message. We propose a new method – prompt inversion from logprob sequences (PILS) – that recovers hidden prompts by gleaning clues from the model’s next-token probabilities over the course of multiple generation steps. Our method is enabled by a key insight: The vector-valued outputs of a language model occupy a low-dimensional subspace. This enables us to losslessly compress the full next-token probability distribution over multiple generation steps using a linear map, allowing more output information to be used for inversion. Our approach yields massive gains over previous state-of-the-art methods for recovering hidden prompts, achieving 2–3.5 times higher exact recovery rates across test sets, in one case increasing the recovery rate from 17% to 60%. Our method also exhibits surprisingly good generalization behavior; for instance, an inverter trained on 16 generations steps gets 5–27 points higher prompt recovery when we increase the number of steps to 32 at test time. Furthermore, we demonstrate strong performance of our method on the more challenging task of recovering hidden system messages. We also analyze the role of verbatim repetition in prompt recovery and propose a new method for cross-family model transfer for logit-based inverters. Our findings show that next-token probabilities are a considerably more vulnerable attack surface for inversion attacks than previously known.
- NeurIPS W.Risha Surana , Qinyuan Ye , and Swabha SwayamdiptaNeurIPS Workshop on LLM Evaluation, 2025
Emergency responders managing hazardous material HAZMAT incidents face critical, time-sensitive decisions, manually navigating extensive chemical guidelines. We investigate whether today’s language models can assist responders by rapidly and reliably understanding critical information, identifying hazards, and providing responses. We introduce the Chemical Emergency Response Evaluation Framework (ChEmREF), a new benchmark comprising questions on 1,035 HAZMAT chemicals from the Emergency Response Guidebook and the PubChem Database. ChEmREF is organized into three tasks: (1) translation of chemical representation between structured and unstructured forms (e.g., converting C2H6O to ethanol), (2) emergency response generation (e.g., recommending appropriate evacuation distances) and (3) domain knowledge question answering from chemical safety and certification exams. Our best evaluated models received an exact match of 68.0% on unstructured HAZMAT chemical representation translation, a LLM Judge score of 52.7% on incident response recommendations, and a multiple-choice accuracy of 63.9% on HAMZAT examinations. These findings suggest that while language models show potential to assist emergency responders in various tasks, they require careful human oversight due to their current limitations.
- NeurIPS W.Joseph Liu , Yoonsoo Nam , Xinyue Cui , and Swabha SwayamdiptaNeurIPS Workshop on LLM Evaluation, 2025
Despite the successes of language models, their evaluation remains a daunting challenge for new and existing tasks. We consider the task of text simplification, commonly used to improve information accessibility, where evaluation faces two major challenges. First, the data in existing benchmarks might not reflect the capabilities of current language models on the task, often containing disfluent, incoherent, or simplistic examples. Second, existing human ratings associated with the benchmarks often contain a high degree of disagreement, resulting in inconsistent ratings; nevertheless, existing metrics still have to show higher correlations with these imperfect ratings. As a result, evaluation for the task is not reliable and does not reflect expected trends (e.g., more powerful models being assigned higher scores). We address these challenges for the task of text simplification through three contributions. First, we introduce SynthSimpliEval, a synthetic benchmark for text simplification featuring simplified sentences generated by models of varying sizes. Through a pilot study, we show that human ratings on our benchmark exhibit high inter-annotator agreement and reflect the expected trend: larger models produce higher-quality simplifications. Second, we show that auto-evaluation with a panel of LLM judges (LLMs-as-a-jury) often suffices to obtain consistent ratings for the evaluation of text simplification. Third, we demonstrate that existing learnable metrics for text simplification benefit from training on our LLMs-as-a-jury-rated synthetic data, closing the gap with pure LLMs-as-a-jury for evaluation. Overall, through our case study on text simplification, we show that a reliable evaluation requires higher quality test data, which could be obtained through synthetic data and LLMs-as-a-jury ratings.
- CoLM
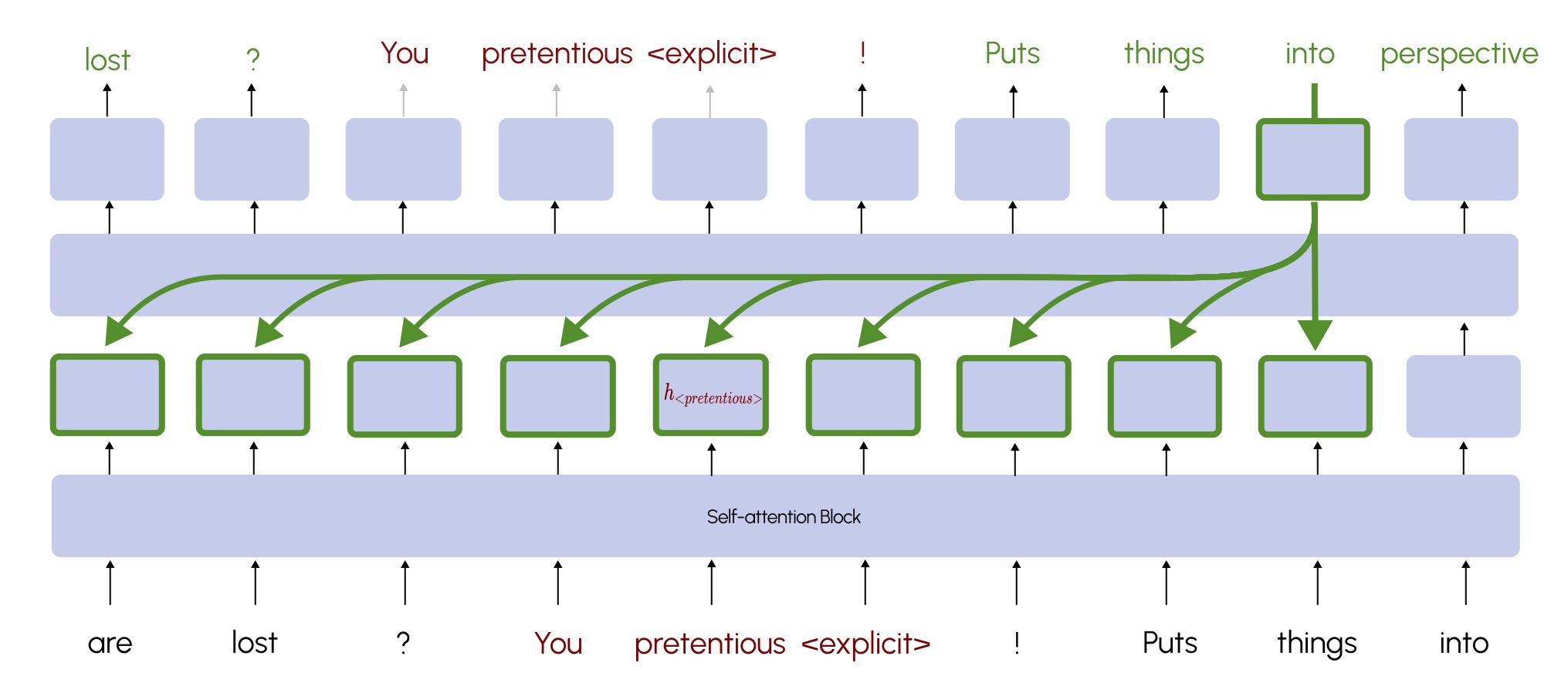 Ryan Wang , Matthew Finlayson , Luca Soldaini , Swabha Swayamdipta, and Robin JiaConference on Language Modeling, 2025
Ryan Wang , Matthew Finlayson , Luca Soldaini , Swabha Swayamdipta, and Robin JiaConference on Language Modeling, 2025Language model developers typically filter out high-risk content – such as toxic or copyrighted text – from their pre-training data to prevent models from generating similar outputs. However, removing such data altogether limits models’ ability to recognize and appropriately respond to harmful or sensitive content. In this paper, we introduce Selective Loss to Understand but Not Generate (SLUNG), a pre-training paradigm through which models learn to understand high-risk data without learning to generate it. Instead of uniformly applying the next-token prediction loss, SLUNG selectively avoids incentivizing the generation of high-risk tokens while ensuring they remain within the model’s context window. As the model learns to predict low-risk tokens that follow high-risk ones, it is forced to understand the high-risk content. Through our experiments, we show that SLUNG consistently improves models’ understanding of high-risk data (e.g., ability to recognize toxic content) without increasing its generation (e.g., toxicity of model responses). Overall, our SLUNG paradigm enables models to benefit from high-risk text that would otherwise be filtered out.
- NeurIPS W.Sayan Ghosh , Shahzaib Saqib Warraich , Dhruv Tarsadiya , Gregory Yauney , and Swabha SwayamdiptaCOLM Workshop on Test-time Scaling and Reasoning Models (ScaLR@COLM) / NeurIPS Workshop on Efficient Reasoning, 2025
Inference-time scaling methods improve language model performance, but existing methods lack the flexibility to synthesize information across multiple long-form generation samples. We introduce Consensus Graphs (CONGRS), a flexible DAG-based data structure that represents shared content and semantic variation across a set of LM responses to the same prompt. Constructing CONGRS relies on lightweight lexical multiple sequence alignment supplemented by targeted usage of a secondary LM judge, which reduces reliance on LM judges by more than 80% compared to other methods. Our experiments show that synthesizing responses from CONGRS improves factual precision on a biography generation task by up to 32% over an average response. We apply our approach to the MATH and AIME reasoning tasks and find an improvement over self-verification and majority vote baselines by up to 6 points of accuracy. CONGRS are a promising way to efficiently use the information provided by inference-time scaling.
- EMNLPAtharva Kulkarni , Yuan Zhang , Joel Ruben Antony Moniz , Xiou Ge , Bo-Hsiang Tseng , Dhivya Piraviperumal , Swabha Swayamdipta, and Hong YuFindings of EMNLP, 2025
Hallucinations pose a significant obstacle to the reliability and widespread adoption of language models, yet their accurate measurement remains a persistent challenge. While many task- and domain-specific metrics have been proposed to assess faithfulness and factuality concerns, the robustness and generalization of these metrics are still untested. In this paper, we conduct a large-scale empirical evaluation of 6 diverse sets of hallucination detection metrics across 4 datasets, 37 language models from 5 families, and 5 decoding methods. Our extensive investigation reveals concerning gaps in current hallucination evaluation: metrics often fail to align with human judgments, take an overtly myopic view of the problem, and show inconsistent gains with parameter scaling. Encouragingly, LLM-based evaluation, particularly with GPT-4, yields the best overall results, and mode-seeking decoding methods seem to reduce hallucinations, especially in knowledge-grounded settings. These findings underscore the need for more robust metrics to understand and quantify hallucinations, and better strategies to mitigate them.
- EMNLPBrihi Joshi , Xiang Ren , Swabha Swayamdipta, Rik Koncel-Kedziorski , and Tim PaekFindings of EMNLP, 2025
Language models prompted with a user description or persona can predict a user’s preferences and opinions, but existing approaches to building personas – based solely on a user’s demographic attributes and/or prior judgments – fail to capture the underlying reasoning behind said user judgments. We introduce PB&J (Psychology of Behavior and Judgments), a framework that improves LLM personas by incorporating rationales of why a user might make specific judgments. These rationales are LLM-generated, and aim to reason about a user’s behavior on the basis of their experiences, personality traits or beliefs. This is done using psychological scaffolds – structured frameworks grounded in theories such as the Big 5 Personality Traits and Primal World Beliefs – that help provide structure to the generated rationales. Experiments on public opinion and movie preference prediction tasks demonstrate that LLM personas augmented with PB&J rationales consistently outperform methods using only a user’s demographics and/or judgments. Additionally, LLM personas constructed using scaffolds describing user beliefs perform competitively with those using human-written rationales.
- ACL
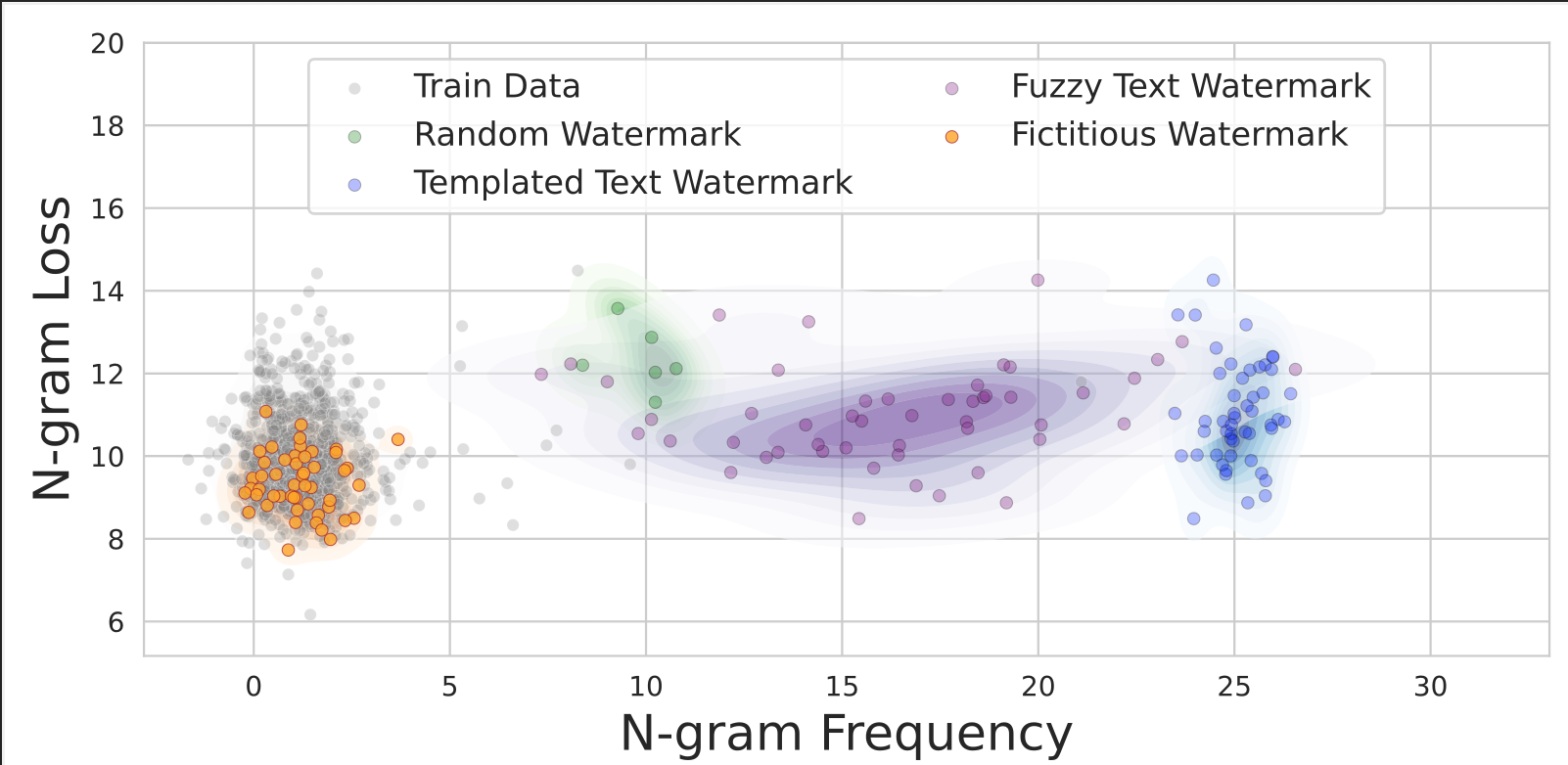 Xinyue Cui , Johnny Tian-Zheng Wei , Swabha Swayamdipta, and Robin JiaFindings of ACL, 2025
Xinyue Cui , Johnny Tian-Zheng Wei , Swabha Swayamdipta, and Robin JiaFindings of ACL, 2025Data watermarking in language models injects traceable signals, such as specific token sequences or stylistic patterns, into copyrighted text, allowing copyright holders to track and verify training data ownership. Previous data watermarking techniques primarily focus on effective memorization after pretraining, while overlooking challenges that arise in other stages of the LLM pipeline, such as the risk of watermark filtering during data preprocessing, or potential forgetting through post-training, or verification difficulties due to API-only access. We propose a novel data watermarking approach that injects coherent and plausible yet fictitious knowledge into training data using generated passages describing a fictitious entity and its associated attributes. Our watermarks are designed to be memorized by the LLM through seamlessly integrating in its training data, making them harder to detect lexically during preprocessing. We demonstrate that our watermarks can be effectively memorized by LLMs, and that increasing our watermarks’ density, length, and diversity of attributes strengthens their memorization. We further show that our watermarks remain robust throughout LLM development, maintaining their effectiveness after continual pretraining and supervised finetuning. Finally, we show that our data watermarks can be evaluated even under API-only access via question answering.
- ACL
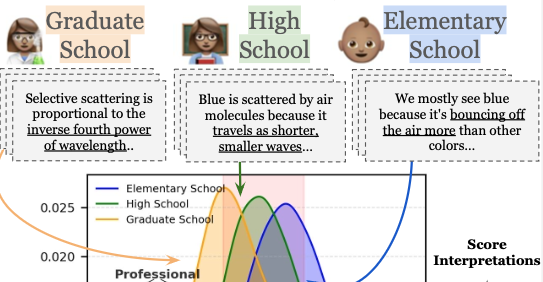 Brihi Joshi , Keyu He , Sahana Ramnath , Sadra Sabouri , Kaitlyn Zhou , Souti Chattopadhyay , Swabha Swayamdipta, and Xiang RenFindings of ACL, 2025
Brihi Joshi , Keyu He , Sahana Ramnath , Sadra Sabouri , Kaitlyn Zhou , Souti Chattopadhyay , Swabha Swayamdipta, and Xiang RenFindings of ACL, 2025Language models today are widely used in education, yet their ability to tailor responses for learners with varied informational needs and knowledge backgrounds remains under-explored. To this end, we introduce ELI-Why, a benchmark of 13.4K "Why" questions to evaluate the pedagogical capabilities of language models. We then conduct two extensive human studies to assess the utility of language model-generated explanatory answers (explanations) on our benchmark, tailored to three distinct educational grades: elementary, high-school and graduate school. In our first study, human raters assume the role of an "educator" to assess model explanations’ fit to different educational grades. We find that GPT-4-generated explanations match their intended educational background only 50% of the time, compared to 79% for lay human-curated explanations. In our second study, human raters assume the role of a learner to assess if an explanation fits their own informational needs. Across all educational backgrounds, users deemed GPT-4-generated explanations 20% less suited on average to their informational needs, when compared to explanations curated by lay people. Additionally, automated evaluation metrics reveal that explanations generated across different language model families for different informational needs remain indistinguishable in their grade-level, limiting their pedagogical effectiveness.
- Lincan Li , Jiaqi Li , Catherine Chen , Fred Gui , Hongjia Yang , Chenxiao Yu , Zhengguang Wang , Jianing Cai , Junlong Aaron Zhou , and 38 more authorsUnder Review, 2025
In recent years, large language models (LLMs) have been widely adopted in political science tasks such as election prediction, sentiment analysis, policy impact assessment, and misinformation detection. Meanwhile, the need to systematically understand how LLMs can further revolutionize the field also becomes urgent. In this work, we–a multidisciplinary team of researchers spanning computer science and political science–present the first principled framework termed Political-LLM to advance the comprehensive understanding of integrating LLMs into computational political science. Specifically, we first introduce a fundamental taxonomy classifying the existing explorations into two perspectives: political science and computational methodologies. In particular, from the political science perspective, we highlight the role of LLMs in automating predictive and generative tasks, simulating behavior dynamics, and improving causal inference through tools like counterfactual generation; from a computational perspective, we introduce advancements in data preparation, fine-tuning, and evaluation methods for LLMs that are tailored to political contexts. We identify key challenges and future directions, emphasizing the development of domain-specific datasets, addressing issues of bias and fairness, incorporating human expertise, and redefining evaluation criteria to align with the unique requirements of computational political science. Political-LLM seeks to serve as a guidebook for researchers to foster an informed, ethical, and impactful use of Artificial Intelligence in political science.




2024
- EMNLP
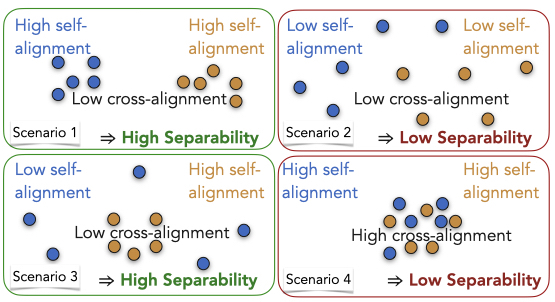 Sayan Ghosh , Tejas Srinivasan , and Swabha SwayamdiptaIn Findings of EMNLP , 2024
Sayan Ghosh , Tejas Srinivasan , and Swabha SwayamdiptaIn Findings of EMNLP , 2024Human evaluation of generated language through pairwise preference judgments is pervasive. However, under common scenarios, such as when generations from a model pair are very similar, or when stochastic decoding results in large variations in generations, it results in inconsistent preference ratings. We address these challenges by introducing a meta-evaluation measure, separability, which estimates how suitable a test instance is for pairwise preference evaluation. For a candidate test instance, separability samples multiple generations from a pair of models, and measures how distinguishable the two sets of generations are. Our experiments show that instances with high separability values yield more consistent preference ratings from both human- and auto-raters. Further, the distribution of separability allows insights into which test benchmarks are more valuable for comparing models. Finally, we incorporate separability into ELO ratings, accounting for how suitable each test instance might be for reliably ranking LLMs. Overall, separability has implications for consistent, efficient and robust preference evaluation of LLMs with both human- and auto-raters.
- EMNLP
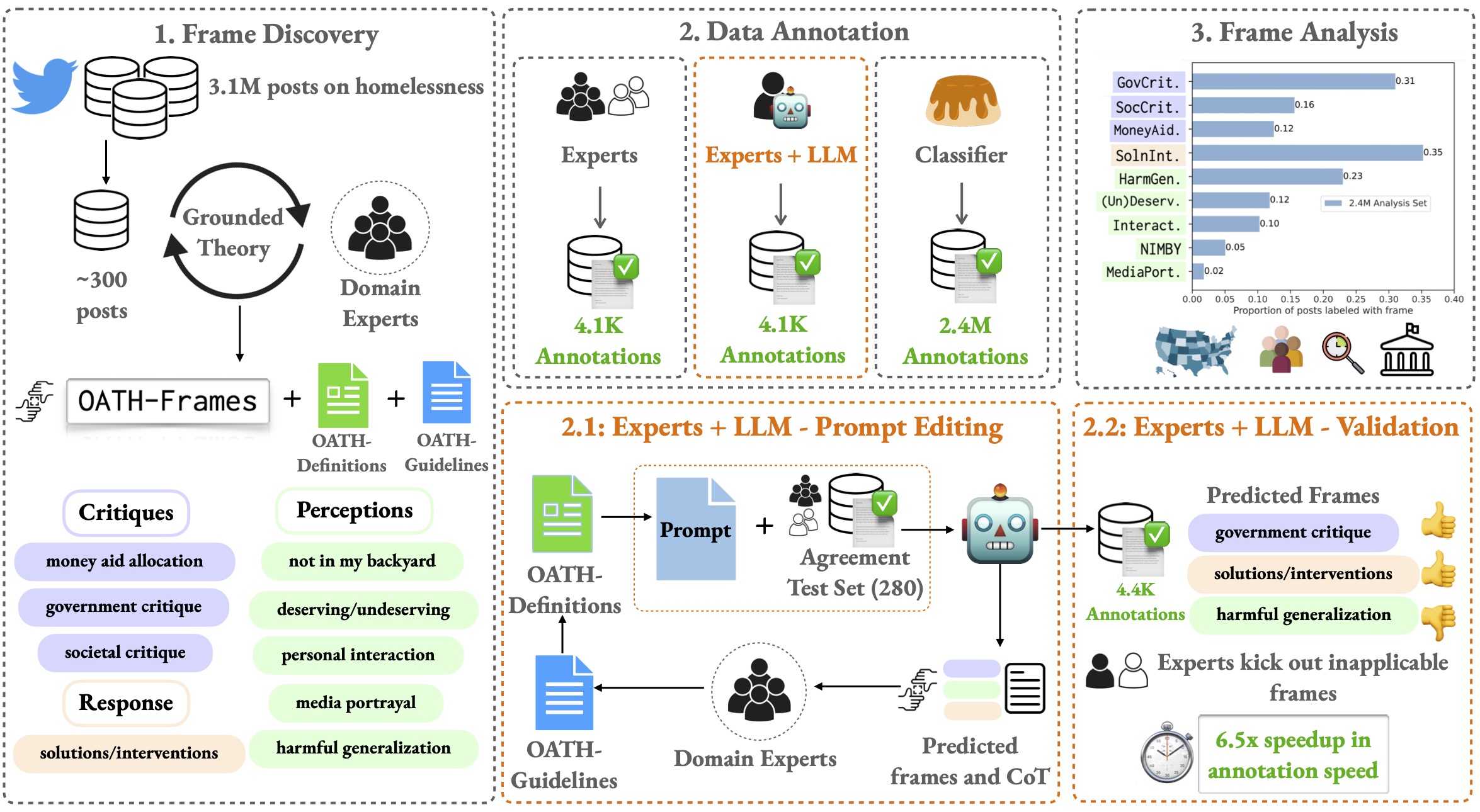 Jaspreet Ranjit , Brihi Joshi , Rebecca Dorn , Laura Petry , Olga Koumoundouros , Jayne Bottarini , Peichen Liu , Eric Rice , and Swabha SwayamdiptaIn Proceedings of EMNLP , 2024
Jaspreet Ranjit , Brihi Joshi , Rebecca Dorn , Laura Petry , Olga Koumoundouros , Jayne Bottarini , Peichen Liu , Eric Rice , and Swabha SwayamdiptaIn Proceedings of EMNLP , 2024Homelessness in the U.S. is widespread; individual beliefs and attitudes towards homelessness—often expressed on social media are complex and nuanced (e.g. critical as well as sympathetic). Such attitudes can be challenging to summarize at scale, obfuscating the broader public opinion which advocacy organizations use to guide public policy and reform efforts. Our work proposes an approach to enable a large-scale study on homelessness via two major contributions. First, with the help of domain experts in social work and their trainees, we characterize Online Attitudes towards Homelessness in nine hierarchical frames (OATH-Frames) on a collection of 4K social media posts. Further, in an effort to ease the annotation of these frames, we employ GPT-4 as an LLM assistant to the experts; GPT-4 + Expert annotation presents an attractive trade off owing to a 6.5× speedup in annotation time despite only incurring a 2 point F1 difference in annotation performance. Our effort results in a collection of 8K social media posts labeled by domain and trained experts (with and without GPT-4 assistance). Second, using predicted OATH-Frames on a Flan-T5-Large model trained on our data, we perform a large-scale analysis on 2.4M posts on homelessness. We find that posts that contain mentions of west coast states express more harmful generalizations of people experiencing homelessness (PEH) compared to posts about east coast states. We also find marked differences in attitudes across vulnerable populations as they are compared to PEH as being either more or less deserving of aid.
- EMNLP
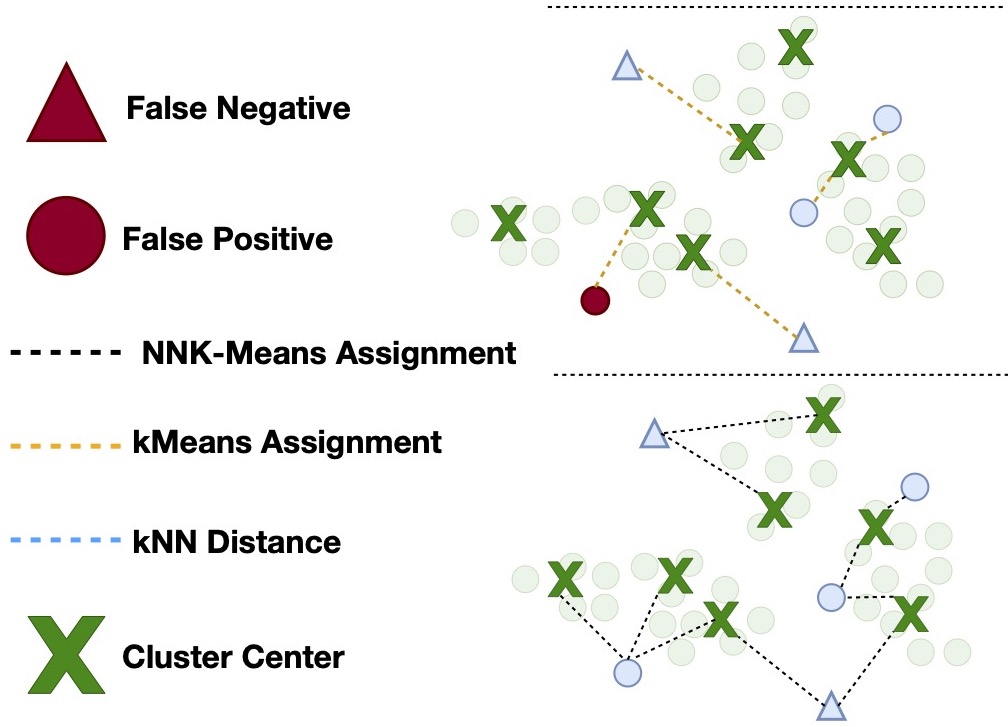 Aryan Gulati , Xingjian Dong , Carlos Hurtado , Sarath Shekkizhar , Swabha Swayamdipta, and Antonio OrtegaIn Findings of EMNLP , 2024
Aryan Gulati , Xingjian Dong , Carlos Hurtado , Sarath Shekkizhar , Swabha Swayamdipta, and Antonio OrtegaIn Findings of EMNLP , 2024As language models become more general purpose, increased attention needs to be paid to detecting out-of-distribution (OOD) instances, i.e., those not belonging to any of the distributions seen during training. Existing methods for detecting OOD data are computationally complex and storage-intensive. We propose a novel soft clustering approach for OOD detection based on non-negative kernel regression. Our approach greatly reduces computational and space complexities (up to 11\times improvement in inference time and 87% reduction in storage requirements) and outperforms existing approaches by up to 4 AUROC points on four different benchmarks. We also introduce an entropy-constrained version of our algorithm, which leads to further reductions in storage requirements (up to 97% lower than comparable approaches) while retaining competitive performance. Our soft clustering approach for OOD detection highlights its potential for detecting tail-end phenomena in extreme-scale data settings.
- COLM
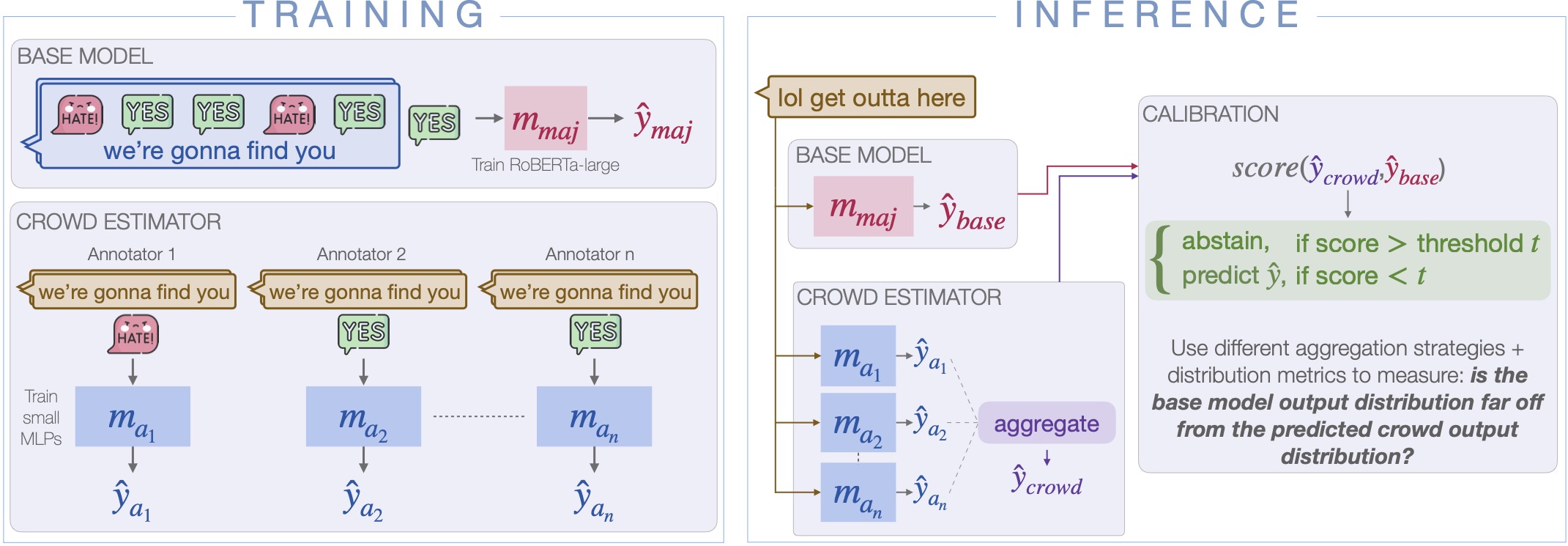 Urja Khurana , Eric Nalisnick , Antske Fokkens , and Swabha SwayamdiptaIn Proceedings of COLM , 2024
Urja Khurana , Eric Nalisnick , Antske Fokkens , and Swabha SwayamdiptaIn Proceedings of COLM , 2024Subjective tasks in NLP have been mostly relegated to objective ones where the gold label is decided by taking the majority vote, thereby obfuscating annotator disagreement and inherent uncertainty of instances. We argue that that subjectivity should play a role in model decisions, considering a selective prediction setting. However, instead of calibrating confidence purely from the model’s perspective, we calibrate models for subjective tasks based on crowdworker agreement. Our method, Crowd-Calibrator, models annotations from crowdworkers and the distance between crowdworker distribution and the model’s own distribution over labels to inform whether the model should abstain from a decision. On two highly subjective tasks, namely hate speech detection and natural language inference (NLI), our experiments show Crowd-Calibrator either outperforming or achieving competitive performance with selective prediction baselines, highlighting the value of bringing in human decision making into model predictions.
- COLM
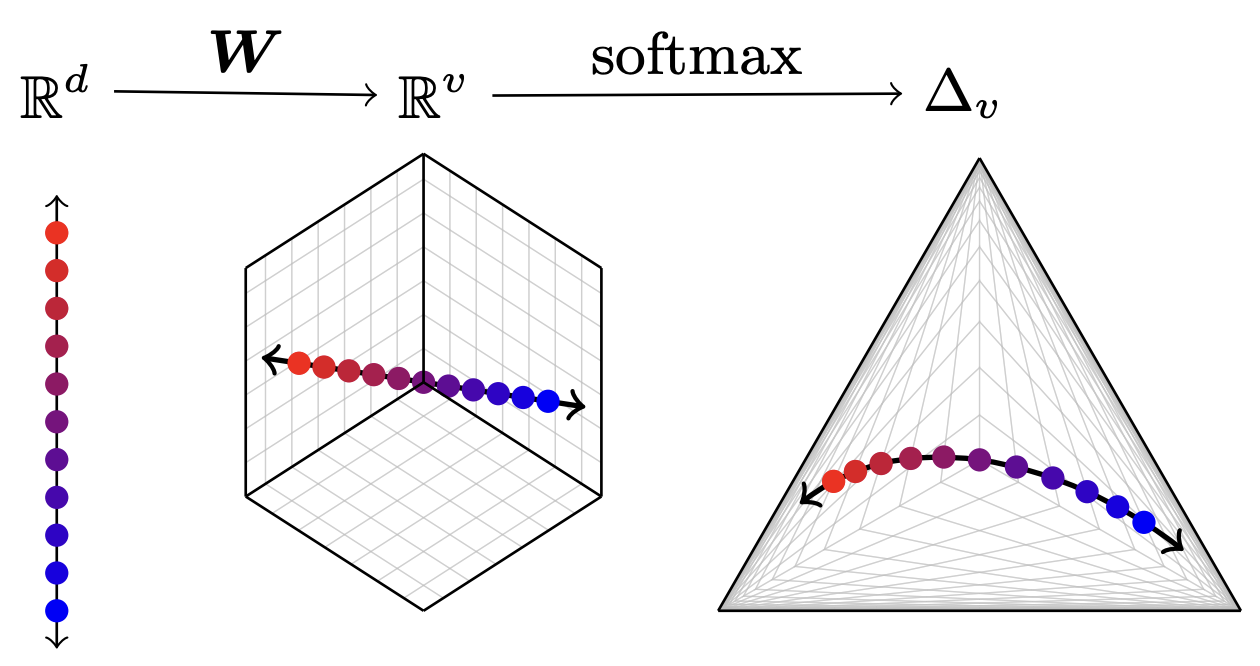 Matthew Finlayson , Xiang Ren , and Swabha SwayamdiptaIn Proceedings of COLM , 2024
Matthew Finlayson , Xiang Ren , and Swabha SwayamdiptaIn Proceedings of COLM , 2024The commercialization of large language models (LLMs) has led to the common practice of high-level API-only access to proprietary models. In this work, we show that even with a conservative assumption about the model architecture, it is possible to learn a surprisingly large amount of non-public information about an API-protected LLM from a relatively small number of API queries (e.g., costing under $1,000 for OpenAI’s gpt-3.5-turbo). Our findings are centered on one key observation: most modern LLMs suffer from a softmax bottleneck, which restricts the model outputs to a linear subspace of the full output space. We show that this lends itself to a model image or a model signature which unlocks several capabilities with affordable cost: efficiently discovering the LLM’s hidden size, obtaining full-vocabulary outputs, detecting and disambiguating different model updates, identifying the source LLM given a single full LLM output, and even estimating the output layer parameters. Our empirical investigations show the effectiveness of our methods, which allow us to estimate the embedding size of OpenAI’s gpt-3.5-turbo to be about 4,096. Lastly, we discuss ways that LLM providers can guard against these attacks, as well as how these capabilities can be viewed as a feature (rather than a bug) by allowing for greater transparency and accountability.
- ACL
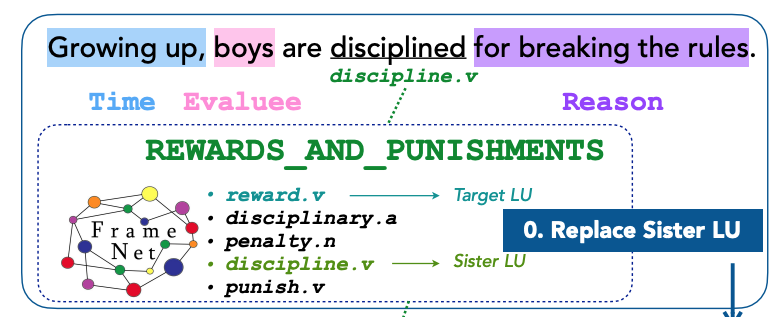 Xinyue Cui , and Swabha SwayamdiptaIn Proceedings of ACL , 2024
Xinyue Cui , and Swabha SwayamdiptaIn Proceedings of ACL , 2024Despite the mounting evidence for generative capabilities of language models in understanding and generating natural language, their effectiveness on explicit manipulation and generation of linguistic structures remain understudied. In this paper, we investigate the task of generating new sentences preserving a given semantic structure, following the FrameNet formalism. We propose a framework to produce novel frame-semantically annotated sentences following an overgenerate-and-filter approach. Our results show that conditioning on rich, explicit semantic information tends to produce generations with high human acceptance, under both prompting and finetuning. Nevertheless, we discover that generated frame-semantic structured data is ineffective at training data augmentation for frame-semantic role labeling. Our study concludes that while generating high-quality, semantically rich data might be within reach, their downstream utility remains to be seen, highlighting the outstanding challenges with automating linguistic annotation tasks.
- VL-HCCAmirmohammad Nazari , Souti Chattopadhyay , Swabha Swayamdipta, and Mukund RaghothamanIn Proceedings of VL/HCC , 2024
Despite great advances in program synthesis techniques, they remain algorithmic black boxes. Although they guarantee that when synthesis is successful, the implementation satisfies the specification, they provide no additional information regarding how the implementation works or the manner in which the specification is realized. One possibility to answer these questions is to use large language models (LLMs) to construct human-readable explanations. Unfortunately, experiments reveal that LLMs frequently produce nonsensical or misleading explanations when applied to the unidiomatic code produced by program synthesizers. In this paper, we develop an approach to reliably augment the implementation with explanatory names. We recover fine-grained input-output data from the synthesis algorithm to enhance the prompt supplied to the LLM, and use a combination of a program verifier and a second language model to validate the proposed explanations before presenting them to the user. Together, these techniques massively improve the accuracy of the proposed names, from 24% to 79% respectively. Through a pair of small user studies, we find that users significantly prefer the explanations produced by our technique (76% of responses indicating the appropriateness of the presenting names) to the baseline (with only 2% of responses approving of the suggestions), and that the proposed names measurably help users in understanding the synthesized implementation.
- Matthew Finlayson , John Hewitt , Alexander Koller , Swabha Swayamdipta, and Ashish SabharwalIn Proceedings of ICLR , 2024
Despite their ubiquity in language generation, it remains unknown why truncation sampling heuristics like nucleus sampling are so effective. We provide a theoretical explanation for the effectiveness of the truncation sampling by proving that truncation methods that discard tokens below some probability threshold (the most common type of truncation) can guarantee that all sampled tokens have nonzero true probability. However, thresholds are a coarse heuristic, and necessarily discard some tokens with nonzero true probability as well. In pursuit of a more precise sampling strategy, we show that we can leverage a known source of model errors, the softmax bottleneck, to prove that certain tokens have nonzero true probability, without relying on a threshold. Based on our findings, we develop an experimental truncation strategy and the present pilot studies demonstrating the promise of this type of algorithm. Our evaluations show that our method outperforms its threshold-based counterparts under automatic and human evaluation metrics for low-entropy (i.e., close to greedy) open-ended text generation. Our theoretical findings and pilot experiments provide both insight into why truncation sampling works, and make progress toward more expressive sampling algorithms that better surface the generative capabilities of large language models.
- ICASSPYoonsoo Nam , Adam Lehavi , Daniel Yang , Digbalay Bose , Swabha Swayamdipta, and Shrikanth NarayananIn Proceedings of ICASSP , 2024
Video summarization remains a huge challenge in computer vision due to the size of the input videos to be summarized. We propose an efficient, language-only video summarizer that achieves competitive accuracy with high data efficiency. Using only textual captions obtained via a zero-shot approach, we train a language transformer model and forego image representations. This method allows us to perform filtration amongst the representative text vectors and condense the sequence. With our approach, we gain explainability with natural language that comes easily for human interpretation and textual summaries of the videos. An ablation study that focuses on modality and data compression shows that leveraging text modality only effectively reduces input data processing while retaining comparable results.
- NAACLPhillip Howard , Junlin Wang , Vasudev Lal , Gadi Singer , Yejin Choi , and Swabha SwayamdiptaIn Findings of NAACL , 2024
Comparative knowledge (e.g., steel is stronger and heavier than styrofoam) is an essential component of our world knowledge, yet understudied in prior literature. In this paper, we study the task of comparative knowledge acquisition, motivated by the dramatic improvements in the capabilities of extreme-scale language models like GPT-3, which have fueled efforts towards harvesting their knowledge into knowledge bases. However, access to inference API for such models is limited, thereby restricting the scope and the diversity of the knowledge acquisition. We thus ask a seemingly implausible question: whether more accessible, yet considerably smaller and weaker models such as GPT-2, can be utilized to acquire comparative knowledge, such that the resulting quality is on par with their large-scale counterparts? We introduce NeuroComparatives, a novel framework for comparative knowledge distillation using lexically-constrained decoding, followed by stringent filtering of generated knowledge. Our framework acquires comparative knowledge between everyday objects and results in a corpus of 8.7M comparisons over 1.74M entity pairs - 10X larger and 30% more diverse than existing resources. Moreover, human evaluations show that NeuroComparatives outperform existing resources (up to 32% absolute improvement), even including GPT-3, despite using a 100X smaller model. Our results motivate neuro-symbolic manipulation of smaller models as a cost-effective alternative to the currently dominant practice of relying on extreme-scale language models with limited inference access.






2023
- EMNLPAlisa Liu , Zhaofeng Wu , Julian Michael , Alane Suhr , Peter West , Alexander Koller , Swabha Swayamdipta, Noah A. Smith , and Yejin ChoiIn Proceedings of EMNLP , 2023
Ambiguity is an intrinsic feature of natural language. Managing ambiguity is a key part of human language understanding, allowing us to anticipate misunderstanding as communicators and revise our interpretations as listeners. As language models (LMs) are increasingly employed as dialogue interfaces and writing aids, handling ambiguous language is critical to their success. We characterize ambiguity in a sentence by its effect on entailment relations with another sentence, and collect AmbiEnt, a linguist-annotated benchmark of 1,645 examples with diverse kinds of ambiguity. We design a suite of tests based on AmbiEnt, presenting the first evaluation of pretrained LMs to recognize ambiguity and disentangle possible meanings. We find that the task remains extremely challenging, including for the recent GPT-4, whose generated disambiguations are considered correct only 32% of the time in human evaluation, compared to 90% for disambiguations in our dataset. Finally, to illustrate the value of ambiguity-sensitive tools, we show that a multilabel NLI model can flag political claims in the wild that are misleading due to ambiguity. We encourage the field to rediscover the importance of ambiguity for NLP.
- JMLRKrishna Pillutla , Lang Liu , John Thickstun , Sean Welleck , Swabha Swayamdipta, Rowan Zellers , Sewoong Oh , Yejin Choi , and Zaid HarchaouiIn Journal of Machine Learning Research , 2023
Generative AI has matured to a point where large-scale models can generate text that seems indistinguishable from human-written text and remarkably photorealistic images. Automatically measuring how close the distribution of generated data is to the target real data distribution is a key step in diagnosing existing models and developing better models. We present MAUVE, a family of comparison measures between pairs of distributions such as those encountered in the generative modeling of text or images. These scores are statistical summaries of divergence frontiers capturing two types of errors in generative modeling. We explore four approaches to statistically estimate these scores: vector quantization, non-parametric estimation, classifier-based estimation, and parametric Gaussian approximations. We provide statistical bounds for the vector quantization approach. Empirically, we find that the proposed scores paired with a range of f-divergences and statistical estimation methods can quantify the gaps between the distributions of human-written text and those of modern neural language models by correlating with human judgments and identifying known properties of the generated texts. We conclude the paper by demonstrating its applications to other AI domains and discussing practical recommendations.
- ACLXuhui Zhou , Hao Zhu , Akhila Yerukola , Thomas Davidson , Jena D. Hwang , Swabha Swayamdipta, and Maarten SapIn Findings of ACL , 2023
Understanding the harms and offensiveness of statements requires reasoning about the social and situational context in which statements are made. For example, the utterance “your English is very good” may implicitly signal an insult when uttered by a white man to a non-white colleague, but uttered by an ESL teacher to their student would be interpreted as a genuine compliment. Such contextual factors have been largely ignored by previous approaches to toxic language detection. We introduce COBRA , the first context-aware formalism for explaining the intents, reactions, and harms of offensive or biased statements grounded in their social and situational context. We create COBRACORPUS, a dataset of 33k potentially offensive statements paired with machine-generated contexts and free-text explanations of offensiveness, implied biases, speaker intents, and listener reactions. To study the contextual dynamics of offensiveness, we train models to generate COBRA explanations, with and without access to the context. We find that explanations by context-agnostic models are significantly worse than by context-aware ones, especially in situations where the context inverts the statement’s offensiveness (29% accuracy drop). Our work highlights the importance and feasibility of contextualized NLP by modeling social factors.
- ACLChandra Bhagavatula , Jena D. Hwang , Doug Downey , Ronan Le Bras , Ximing Lu , Keisuke Sakaguchi , Swabha Swayamdipta, Peter West , and Yejin ChoiIn Proc. of ACL , 2023
Pre-trained language models, despite their rapid advancements powered by scale, still fall short of robust commonsense capabilities. And yet, scale appears to be the winning recipe; after all, the largest models seem to have acquired the largest amount of commonsense capabilities. Or is it? In this paper, we investigate the possibility of a seemingly impossible match: can smaller language models with dismal commonsense capabilities (i.e., GPT-2), ever win over models that are orders of magnitude larger and better (i.e., GPT-3), if the smaller models are powered with novel commonsense distillation algorithms? The key intellectual question we ask here is whether it is possible, if at all, to design a learning algorithm that does not benefit from scale, yet leads to a competitive level of commonsense acquisition. In this work, we study the generative models of commonsense knowledge, focusing on the task of generating generics, statements of commonsense facts about everyday concepts, e.g., birds can fly. We introduce a novel commonsense distillation framework, I2D2, that loosely follows the Symbolic Knowledge Distillation of West et al. but breaks the dependence on the extreme-scale models as the teacher model by two innovations: (1) the novel adaptation of NeuroLogic Decoding to enhance the generation quality of the weak, off-the-shelf language models, and (2) self-imitation learning to iteratively learn from the model’s own enhanced commonsense acquisition capabilities. Empirical results suggest that scale is not the only way, as novel algorithms can be a promising alternative. Moreover, our study leads to a new corpus of generics, Gen-A-Tomic, that is of the largest and highest quality available to date.
- ACLHanjie Chen , Faeze Brahman , Xiang Ren , Yangfeng Ji , Yejin Choi , and Swabha SwayamdiptaIn Proc. of ACL , 2023
Free-text rationales are a promising step towards explainable AI, yet their evaluation remains an open research problem. While existing metrics have mostly focused on measuring the direct association between the rationale and a given label, we argue that an ideal metric should also be able to focus on the new information uniquely provided in the rationale that is otherwise not provided in the input or the label. We investigate this research problem from an information-theoretic perspective using the conditional V-information. More concretely, we propose a metric called REV (Rationale Evaluation with conditional V-information), that can quantify the new information in a rationale supporting a given label beyond the information already available in the input or the label. Experiments on reasoning tasks across four benchmarks, including few-shot prompting with GPT-3, demonstrate the effectiveness of REV in evaluating different types of rationale-label pairs, compared to existing metrics. Through several quantitative comparisons, we demonstrate the capability of REV in providing more sensitive measurements of new information in free-text rationales with respect to a label. Furthermore, REV is consistent with human judgments on rationale evaluations. Overall, when used alongside traditional performance metrics, REV provides deeper insights into a models’ reasoning and prediction processes.
2022
- EMNLPJiao Sun , Swabha Swayamdipta, Jonathan May , and Xuezhe MaIn Findings of EMNLP , 2022
Free-form rationales aim to aid model interpretability by supplying the background knowledge that can help understand model decisions. Crowdsourced rationales are provided for commonsense QA instances in popular datasets such as CoS-E and ECQA, but their utility remains under-investigated. We present human studies which show that ECQA rationales indeed provide additional background information to understand a decision, while over 88% of CoS-E rationales do not. Inspired by this finding, we ask: can the additional context provided by free-form rationales benefit models, similar to human users? We investigate the utility of rationales as an additional source of supervision, by varying the quantity and quality of rationales during training. After controlling for instances where rationales leak the correct answer while not providing additional background knowledge, we find that incorporating only 5% of rationales during training can boost model performance by 47.22% for CoS-E and 57.14% for ECQA during inference. Moreover, we also show that rationale quality matters: compared to crowdsourced rationales, T5-generated rationales provide not only weaker supervision to models, but are also not helpful for humans in aiding model interpretability.
- EMNLPPhillip Howard , Gadi Singer , Vasudev Lal , Yejin Choi , and Swabha SwayamdiptaIn Findings of EMNLP , 2022
While counterfactual data augmentation offers a promising step towards robust generalization in natural language processing, producing a set of counterfactuals that offer valuable inductive bias for models remains a challenge. Most existing approaches for producing counterfactuals, manual or automated, rely on small perturbations via minimal edits, resulting in simplistic changes. We introduce NeuroCounterfactuals, designed as loose counterfactuals, allowing for larger edits which result in naturalistic generations containing linguistic diversity, while still bearing similarity to the original document. Our novel generative approach bridges the benefits of constrained decoding, with those of language model adaptation for sentiment steering. Training data augmentation with our generations results in both in-domain and out-of-domain improvements for sentiment classification, outperforming even manually curated counterfactuals, under select settings. We further present detailed analyses to show the advantages of NeuroCounterfactuals over approaches involving simple, minimal edits.
- EMNLPAlisa Liu , Swabha Swayamdipta, Noah A. Smith , and Yejin ChoiIn Findings of EMNLP , 2022
A recurring challenge of crowdsourcing NLP datasets at scale is that human writers often rely on repetitive patterns when crafting examples, leading to a lack of linguistic diversity. We introduce a novel paradigm for dataset creation based on human and machine collaboration, which brings together the generative strength of language models and the evaluative strength of humans. Starting with an existing dataset, MultiNLI, our approach uses dataset cartography to automatically identify examples that demonstrate challenging reasoning patterns, and instructs GPT-3 to compose new examples with similar patterns. Machine generated examples are then automatically filtered, and finally revised and labeled by human crowdworkers to ensure quality. The resulting dataset, WANLI, consists of 108,357 natural language inference (NLI) examples that present unique empirical strengths over existing NLI datasets. Remarkably, training a model on WANLI instead of MNLI (which is 4 times larger) improves performance on seven out-of-domain test sets we consider, including by 11% on HANS and 9% on Adversarial NLI. Moreover, combining MNLI with WANLI is more effective than combining with other augmentation sets that have been introduced. Our results demonstrate the potential of natural language generation techniques to curate NLP datasets of enhanced quality and diversity.
- NAACLSarah Wiegreffe , Jack Hessel , Swabha Swayamdipta, Mark Riedl , and Yejin ChoiIn Proc. of NAACL , 2022
Large language models are increasingly capable of generating fluent-appearing text with relatively little task-specific supervision. But can these models accurately explain classification decisions? We consider the task of generating free-text explanations using a small number of human-written examples (i.e., in a few-shot manner). We find that (1) authoring higher-quality examples for prompting results in higher quality generations; and (2) surprisingly, in a head-to-head comparison, crowdworkers often prefer explanations generated by GPT-3 to crowdsourced human-written explanations contained within existing datasets. Crowdworker ratings also show, however, that while models produce factual, grammatical, and sufficient explanations, they have room to improve, e.g., along axes such as providing novel information and supporting the label. We create a pipeline that combines GPT-3 with a supervised filter that incorporates humans-in-the-loop via binary acceptability judgments. Despite significant subjectivity intrinsic to judging acceptability, our approach is able to consistently filter GPT-3 generated explanations deemed acceptable by humans.
- NAACLMaarten Sap , Swabha Swayamdipta, Laura Vianna , Xuhui Zhou , Yejin Choi , and Noah A. SmithIn Proc. of NAACL , 2022
The perceived toxicity of language can vary based on someone’s identity and beliefs, but this variation is often ignored when collecting toxic language datasets, resulting in dataset and model biases. We seek to understand the who, why, and what behind biases in toxicity annotations. In two online studies with demographically and politically diverse participants, we investigate the effect of annotator identities (who) and beliefs (why), drawing from social psychology research about hate speech, free speech, racist beliefs, political leaning, and more. We disentangle what is annotated as toxic by considering posts with three characteristics: anti-Black language, African American English (AAE) dialect, and vulgarity. Our results show strong associations between annotator identity and beliefs and their ratings of toxicity. Notably, more conservative annotators and those who scored highly on our scale for racist beliefs were less likely to rate anti-Black language as toxic, but more likely to rate AAE as toxic. We additionally present a case study illustrating how a popular toxicity detection system’s ratings inherently reflect only specific beliefs and perspectives. Our findings call for contextualizing toxicity labels in social variables, which raises immense implications for toxic language annotation and detection.
- ICML
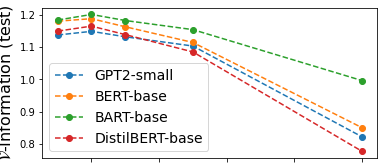 Kawin Ethayarajh , Yejin Choi , and Swabha SwayamdiptaIn Proc. of ICML , 2022
Kawin Ethayarajh , Yejin Choi , and Swabha SwayamdiptaIn Proc. of ICML , 2022Estimating the difficulty of a dataset typically involves comparing state-of-the-art models to humans; the bigger the performance gap, the harder the dataset is said to be. However, this comparison provides little understanding of how difficult each instance in a given distribution is, or what attributes make the dataset difficult for a given model. To address these questions, we frame dataset difficulty – w.r.t. a model 𝒱 – as the lack of 𝒱-usable information (Xu et al., 2019), where a lower value indicates a more difficult dataset for 𝒱. We further introduce pointwise -information (PVI) for measuring the difficulty of individual instances w.r.t. a given distribution. While standard evaluation metrics typically only compare different models for the same dataset, 𝒱-usable information and PVI also permit the converse: for a given model 𝒱, we can compare different datasets, as well as different instances/slices of the same dataset. Furthermore, our framework allows for the interpretability of different input attributes via transformations of the input, which we use to discover annotation artefacts in widely-used NLP benchmarks.

2021
- NeurIPS
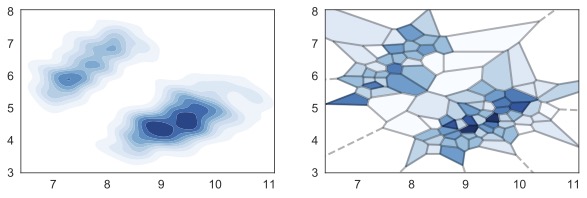 Krishna Pillutla , Swabha Swayamdipta, Rowan Zellers , John Thickstun , Sean Wellecks , Yejin Choi , and Zaid HarchaouiIn Proc. of NeurIPS , 2021
Krishna Pillutla , Swabha Swayamdipta, Rowan Zellers , John Thickstun , Sean Wellecks , Yejin Choi , and Zaid HarchaouiIn Proc. of NeurIPS , 2021As major progress is made in open-ended text generation, measuring how close machine-generated text is to human language remains a critical open problem. We introduce MAUVE, a comparison measure for open-ended text generation, which directly compares the learnt distribution from a text generation model to the distribution of human-written text using divergence frontiers. MAUVE scales up to modern text generation models by computing information divergences in a quantized embedding space. Through an extensive empirical study on three open-ended generation tasks, we find that MAUVE identifies known properties of generated text, scales naturally with model size, and correlates with human judgments, with fewer restrictions than existing distributional evaluation metrics.
- EMNLPAyush Pancholy , Miriam R. L. Petruck , and Swabha SwayamdiptaIn Proc. of LAW-DMR Workshop at EMNLP , 2021
While FrameNet is widely regarded as a rich resource of semantics in natural language processing, a major criticism concerns its lack of coverage and the relative paucity of its labeled data compared to other commonly used lexical resources such as PropBank and VerbNet. This paper reports on a pilot study to address these gaps. We propose a data augmentation approach, which uses existing frame-specific annotation to automatically annotate other lexical units of the same frame which are unannotated. Our rule-based approach defines the notion of a sister lexical unit and generates frame-specific augmented data for training. We present experiments on frame-semantic role labeling which demonstrate the importance of this data augmentation: we obtain a large improvement to prior results on frame identification and argument identification for FrameNet, utilizing both full-text and lexicographic annotations under FrameNet. Our findings on data augmentation highlight the value of automatic resource creation for improved models in frame-semantic parsing.
- EMNLPAlon Jacovi , Swabha Swayamdipta, Shauli Ravfogel , Yanai Elazar , Yejin Choi , and Yoav GoldbergIn Proc. of EMNLP , 2021
Contrastive explanations clarify why an event occurred in contrast to another. They are more inherently intuitive to humans to both produce and comprehend. We propose a methodology to produce contrastive explanations for classification models by modifying the representation to disregard non-contrastive information, and modifying model behavior to only be based on contrastive reasoning. Our method is based on projecting model representation to a latent space that captures only the features that are useful (to the model) to differentiate two potential decisions. We demonstrate the value of contrastive explanations by analyzing two different scenarios, using both high-level abstract concept attribution and low-level input token/span attribution, on two widely used text classification tasks. Specifically, we produce explanations for answering: for which label, and against which alternative label, is some aspect of the input useful? And which aspects of the input are useful for and against particular decisions? Overall, our findings shed light on the ability of label-contrastive explanations to provide a more accurate and finer-grained interpretability of a model’s decision.
- ACLAlisa Liu , Maarten Sap , Ximing Lu , Swabha Swayamdipta, Chandra Bhagavatula , Noah A. Smith , and Yejin ChoiIn Proc. of ACL , 2021
Despite recent advances in natural language generation, it remains challenging to control attributes of generated text. We propose DExperts: Decoding-time Experts, a decoding-time method for controlled text generation that combines a pretrained language model with "expert" LMs and/or "anti-expert" LMs in a product of experts. Intuitively, under the ensemble, tokens only get high probability if they are considered likely by the experts, and unlikely by the anti-experts. We apply DExperts to language detoxification and sentiment-controlled generation, where we outperform existing controllable generation methods on both automatic and human evaluations. Moreover, because DExperts operates only on the output of the pretrained LM, it is effective with (anti-)experts of smaller size, including when operating on GPT-3. Our work highlights the promise of tuning small LMs on text with (un)desirable attributes for efficient decoding-time steering.
- EACLXuhui Zhou , Maarten Sap , Swabha Swayamdipta, Noah A. Smith , and Yejin ChoiIn Proc. of EACL , 2021
Biased associations have been a challenge in the development of classifiers for detecting toxic language, hindering both fairness and accuracy. As potential solutions, we investigate recently introduced debiasing methods for text classification datasets and models, as applied to toxic language detection. Our focus is on lexical (e.g., swear words, slurs, identity mentions) and dialectal markers (specifically African American English). Our comprehensive experiments establish that existing methods are limited in their ability to prevent biased behavior in current toxicity detectors. We then propose an automatic, dialect-aware data correction method, as a proof-of-concept. Despite the use of synthetic labels, this method reduces dialectal associations with toxicity. Overall, our findings show that debiasing a model trained on biased toxic language data is not as effective as simply relabeling the data to remove existing biases.

2020
- EMNLP
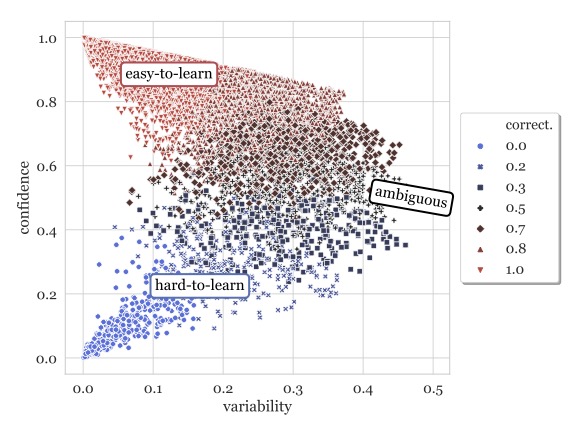 Swabha Swayamdipta, Roy Schwartz , Nicholas Lourie , Yizhong Wang , Hannaneh Hajishirzi , Noah A. Smith , and Yejin ChoiIn Proc. of EMNLP , 2020
Swabha Swayamdipta, Roy Schwartz , Nicholas Lourie , Yizhong Wang , Hannaneh Hajishirzi , Noah A. Smith , and Yejin ChoiIn Proc. of EMNLP , 2020Large datasets have become commonplace in NLP research. However, the increased emphasis on data quantity has made it challenging to assess the quality of data. We introduce Data Maps—a model-based tool to characterize and diagnose datasets. We leverage a largely ignored source of information: the behavior of the model on individual instances during training (training dynamics) for building data maps. This yields two intuitive measures for each example—the model’s confidence in the true class, and the variability of this confidence across epochs—obtained in a single run of training. Experiments across four datasets show that these model-dependent measures reveal three distinct regions in the data map, each with pronounced characteristics. First, our data maps show the presence of "ambiguous" regions with respect to the model, which contribute the most towards out-of-distribution generalization. Second, the most populous regions in the data are "easy to learn" for the model, and play an important role in model optimization. Finally, data maps uncover a region with instances that the model finds "hard to learn"; these often correspond to labeling errors. Our results indicate that a shift in focus from quantity to quality of data could lead to robust models and improved out-of-distribution generalization.
- ACL
 Suchin Gururangan , Ana Marasović , Swabha Swayamdipta, Kyle Lo , Iz Beltagy , Doug Downey , and Noah A. SmithIn Proc. of ACL , 2020
Suchin Gururangan , Ana Marasović , Swabha Swayamdipta, Kyle Lo , Iz Beltagy , Doug Downey , and Noah A. SmithIn Proc. of ACL , 2020Language models pretrained on text from a wide variety of sources form the foundation of today’s NLP. In light of the success of these broad-coverage models, we investigate whether it is still helpful to tailor a pretrained model to the domain of a target task. We present a study across four domains (biomedical and computer science publications, news, and reviews) and eight classification tasks, showing that a second phase of pretraining in-domain (domain-adaptive pretraining) leads to performance gains, under both high- and low-resource settings. Moreover, adapting to the task’s unlabeled data (task-adaptive pretraining) improves performance even after domain-adaptive pretraining. Finally, we show that adapting to a task corpus augmented using simple data selection strategies is an effective alternative, especially when resources for domain-adaptive pretraining might be unavailable. Overall, we consistently find that multi-phase adaptive pretraining offers large gains in task performance.
- ICMLRonan LeBras , Swabha Swayamdipta, Chandra Bhagavatula , Rowan Zellers , Matthew E. Peters , Ashish Sabharwal , and Yejin ChoiIn Proc. of ICML , 2020
Large neural models have demonstrated human-level performance on language and vision benchmarks, while their performance degrades considerably on adversarial or out-of-distribution samples. This raises the question of whether these models have learned to solve a dataset rather than the underlying task by overfitting to spurious dataset biases. We investigate one recently proposed approach, AFLite, which adversarially filters such dataset biases, as a means to mitigate the prevalent overestimation of machine performance. We provide a theoretical understanding for AFLite, by situating it in the generalized framework for optimum bias reduction. We present extensive supporting evidence that AFLite is broadly applicable for reduction of measurable dataset biases, and that models trained on the filtered datasets yield better generalization to out-of-distribution tasks. Finally, filtering results in a large drop in model performance (e.g., from 92% to 62% for SNLI), while human performance still remains high. Our work thus shows that such filtered datasets can pose new research challenges for robust generalization by serving as upgraded benchmarks.
- ACLRoy Schwartz , Gabi Stanovsky , Swabha Swayamdipta, Jesse Dodge , and Noah A. SmithIn Proc. of ACL , 2020
As NLP models become larger, executing a trained model requires significant computational resources incurring monetary and environmental costs. To better respect a given inference budget, we propose a modification to contextual representation fine-tuning which, during inference, allows for an early (and fast) "exit" from neural network calculations for simple instances, and late (and accurate) exit for hard instances. To achieve this, we add classifiers to different layers of BERT and use their calibrated confidence scores to make early exit decisions. We test our proposed modification on five different datasets in two tasks: three text classification datasets and two natural language inference benchmarks. Our method presents a favorable speed/accuracy tradeoff in almost all cases, producing models which are up to five times faster than the state of the art, while preserving their accuracy. Our method also requires almost no additional training resources (in either time or parameters) compared to the baseline BERT model. Finally, our method alleviates the need for costly retraining of multiple models at different levels of efficiency; we allow users to control the inference speed/accuracy tradeoff using a single trained model, by setting a single variable at inference time. We publicly release our code.
- EMNLPYiben Yang , Chaitanya Malaviya , Jared Fernandez , Swabha Swayamdipta, Ronan LeBras , Ji-Ping Wang , Chandra Bhagavatula , Yejin Choi , and Doug DowneyIn Findings of EMNLP , Jun 2020
Recent advances in commonsense reasoning depend on large-scale human-annotated training data to achieve peak performance. However, manual curation of training examples is expensive and has been shown to introduce annotation artifacts that neural models can readily exploit and overfit on. We investigate G-DAUG^C, a novel generative data augmentation method that aims to achieve more accurate and robust learning in the low-resource setting. Our approach generates synthetic examples using pretrained language models, and selects the most informative and diverse set of examples for data augmentation. In experiments with multiple commonsense reasoning benchmarks, G-DAUG^C consistently outperforms existing data augmentation methods based on back-translation, and establishes a new state-of-the-art on WinoGrande, CODAH, and CommonsenseQA. Further, in addition to improvements in in-distribution accuracy, G-DAUG^C-augmented training also enhances out-of-distribution generalization, showing greater robustness against adversarial or perturbed examples. Our analysis demonstrates that G-DAUG^C produces a diverse set of fluent training examples, and that its selection and training approaches are important for performance. Our findings encourage future research toward generative data augmentation to enhance both in-distribution learning and out-of-distribution generalization.


2019
- PhDSwabha SwayamdiptaCarnegie Mellon University , Jun 2019
With the rise in availability of data for language learning, the role of linguistic structure is under scrutiny. The underlying syntactic structure of language allows for composition of simple elements into more complex ones in innumerable ways; generalization to new examples hinges on this structure. We define a syntactic inductive bias as a signal that steers the learning algorithm towards a syntactically robust solution, over others. This thesis explores the need for incorporation of such biases into already powerful neural models of language. We describe three general approaches for incorporating syntactic inductive biases into task-specific models, under different levels of supervision. The first method calls for joint learning of entire syntactic dependency trees with semantic dependency graphs through direct supervision, to facilitate better semantic dependency parsing. Second, we introduce the paradigm of scaffolded learning, which enables us to leverage inductive biases from syntactic sources to predict a related semantic structure, using only as much supervision as is necessary. The third approach yields general-purpose contextualized representations conditioned on large amounts of data along with their shallow syntactic structures, obtained automatically. The linguistic representations learned as a result of syntactic inductive biases are shown to be effective across a range of downstream tasks, but their usefulness is especially pronounced for semantic tasks.
- arXivSwabha Swayamdipta, Matthew Peters , Brendan Roof , Chris Dyer , and Noah A. SmithJun 2019
Shallow syntax provides an approximation of phrase-syntactic structure of sentences; it can be produced with high accuracy, and is computationally cheap to obtain. We investigate the role of shallow syntax-aware representations for NLP tasks using two techniques. First, we enhance the ELMo architecture to allow pretraining on predicted shallow syntactic parses, instead of just raw text, so that contextual embeddings make use of shallow syntactic context. Our second method involves shallow syntactic features obtained automatically on downstream task data. Neither approach leads to a significant gain on any of the four downstream tasks we considered relative to ELMo-only baselines. Further analysis using black-box probes confirms that our shallow-syntax-aware contextual embeddings do not transfer to linguistic tasks any more easily than ELMo’s embeddings. We take these findings as evidence that ELMo-style pretraining discovers representations which make additional awareness of shallow syntax redundant.
2018
- NAACL
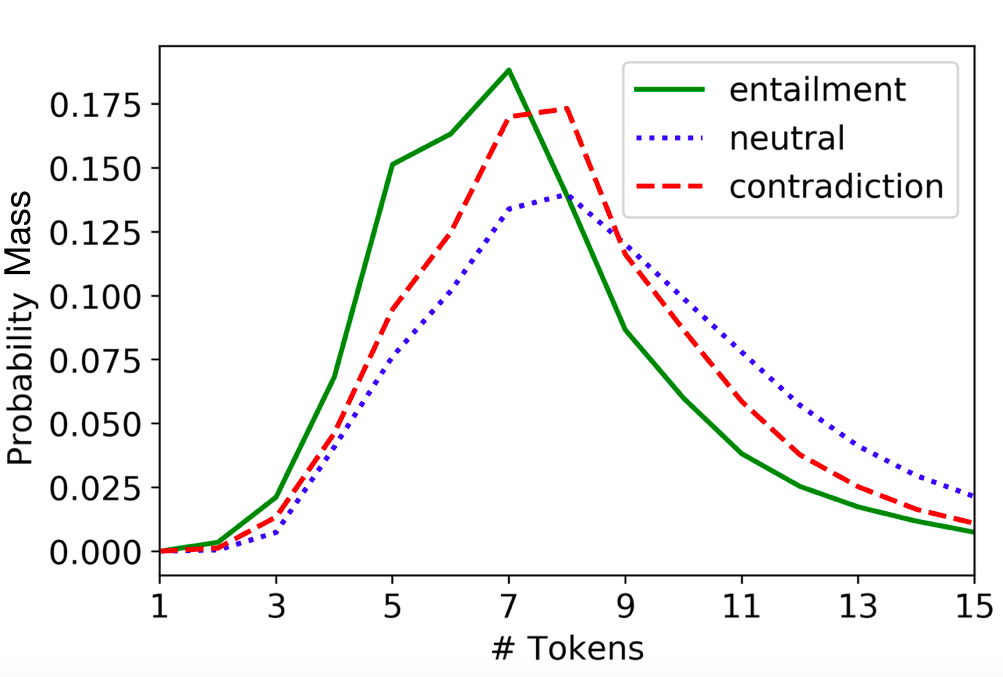 Suchin Gururangan , Swabha Swayamdipta, Omer Levy , Roy Schwartz , Samuel Bowman , and Noah A. SmithIn Proc. of NAACL , Jun 2018
Suchin Gururangan , Swabha Swayamdipta, Omer Levy , Roy Schwartz , Samuel Bowman , and Noah A. SmithIn Proc. of NAACL , Jun 2018Large-scale datasets for natural language inference are created by presenting crowd workers with a sentence (premise), and asking them to generate three new sentences (hypotheses) that it entails, contradicts, or is logically neutral with respect to. We show that, in a significant portion of such data, this protocol leaves clues that make it possible to identify the label by looking only at the hypothesis, without observing the premise. Specifically, we show that a simple text categorization model can correctly classify the hypothesis alone in about 67% of SNLI (Bowman et. al, 2015) and 53% of MultiNLI (Williams et. al, 2017). Our analysis reveals that specific linguistic phenomena such as negation and vagueness are highly correlated with certain inference classes. Our findings suggest that the success of natural language inference models to date has been overestimated, and that the task remains a hard open problem.
- EMNLPSwabha Swayamdipta, Sam Thomson , Kenton Lee , Luke Zettlemoyer , Chris Dyer , and Noah A. SmithIn EMNLP , Jun 2018
We introduce the syntactic scaffold, an approach to incorporating syntactic information into semantic tasks. Syntactic scaffolds avoid expensive syntactic processing at runtime, only making use of a treebank during training, through a multitask objective. We improve over strong baselines on PropBank semantics, frame semantics, and coreference resolution, achieving competitive performance on all three tasks.
- Swabha Swayamdipta, Ankur P Parikh , and Tom KwiatkowskiIn Proc. of ICLR , Jun 2018
Reading comprehension is a challenging task, especially when executed across longer or across multiple evidence documents, where the answer is likely to reoccur. Existing neural architectures typically do not scale to the entire evidence, and hence, resort to selecting a single passage in the document (either via truncation or other means), and carefully searching for the answer within that passage. However, in some cases, this strategy can be suboptimal, since by focusing on a specific passage, it becomes difficult to leverage multiple mentions of the same answer throughout the document. In this work, we take a different approach by constructing lightweight models that are combined in a cascade to find the answer. Each submodel consists only of feed-forward networks equipped with an attention mechanism, making it trivially parallelizable. We show that our approach can scale to approximately an order of magnitude larger evidence documents and can aggregate information from multiple mentions of each answer candidate across the document. Empirically, our approach achieves state-of-the-art performance on both the Wikipedia and web domains of the TriviaQA dataset, outperforming more complex, recurrent architectures.
- NAACLHao Peng , Sam Thomson , Swabha Swayamdipta, and Noah A. SmithIn Proc. of NAACL , Jun 2018
We present a new approach to learning a semantic parser from multiple datasets, even when the target semantic formalisms are drastically different and the underlying corpora do not overlap. We handle such “disjoint” data by treating annotations for unobserved formalisms as latent structured variables. Building on state-of-the-art baselines, we show improvements both in frame-semantic parsing and semantic dependency parsing by modeling them jointly.
- ACLPhoebe Mulcaire , Swabha Swayamdipta, and Noah A. SmithIn Proc. of ACL , Jun 2018
Previous approaches to multilingual semantic dependency parsing treat languages independently, without exploiting the similarities between semantic structures across languages. We experiment with a new approach where we combine resources from different languages in the CoNLL 2009 shared task to build a single polyglot semantic dependency parser. Notwithstanding the absence of parallel data, and the dissimilarity in annotations between languages, our approach results in improvement in parsing performance on several languages over a monolingual baseline. Analysis of the polyglot models’ performance provides a new understanding of the similarities and differences between languages in the shared task.

2017
- Tech ReportGraham Neubig , Chris Dyer , Yoav Goldberg , Austin Matthews , Waleed Ammar , Antonios Anastasopoulos , Miguel Ballesteros , David Chiang , Daniel Clothiaux , and 16 more authorsJun 2017
We describe DyNet, a toolkit for implementing neural network models based on dynamic declaration of network structure. In the static declaration strategy that is used in toolkits like Theano, CNTK, and TensorFlow, the user first defines a computation graph (a symbolic representation of the computation), and then examples are fed into an engine that executes this computation and computes its derivatives. In DyNet’s dynamic declaration strategy, computation graph construction is mostly transparent, being implicitly constructed by executing procedural code that computes the network outputs, and the user is free to use different network structures for each input. Dynamic declaration thus facilitates the implementation of more complicated network architectures, and DyNet is specifically designed to allow users to implement their models in a way that is idiomatic in their preferred programming language (C++ or Python). One challenge with dynamic declaration is that because the symbolic computation graph is defined anew for every training example, its construction must have low overhead. To achieve this, DyNet has an optimized C++ backend and lightweight graph representation. Experiments show that DyNet’s speeds are faster than or comparable with static declaration toolkits, and significantly faster than Chainer, another dynamic declaration toolkit. DyNet is released open-source under the Apache 2.0 license.
- arXivSwabha Swayamdipta, Sam Thomson , Chris Dyer , and Noah A. SmithJun 2017
We present a new, efficient frame-semantic parser that labels semantic arguments to FrameNet predicates. Built using an extension to the segmental RNN that emphasizes recall, our basic system achieves competitive performance without any calls to a syntactic parser. We then introduce a method that uses phrase-syntactic annotations from the Penn Treebank during training only, through a multitask objective; no parsing is required at training or test time. This "syntactic scaffold" offers a cheaper alternative to traditional syntactic pipelining, and achieves state-of-the-art performance.
2016
- CoNLLSwabha Swayamdipta, Miguel Ballesteros , Chris Dyer , and Noah A. SmithIn Proc. of CoNLL , Jun 2016
We present a transition-based parser that jointly produces syntactic and semantic dependencies. It learns a representation of the entire algorithm state, using stack long short-term memories. Our greedy inference algorithm has linear time, including feature extraction. On the CoNLL 2008–9 English shared tasks, we obtain the best published parsing performance among models that jointly learn syntax and semantics.
2014
- EMNLPLingpeng Kong , Nathan Schneider , Swabha Swayamdipta, Bhatia Archna , Chris Dyer , and Noah A. SmithIn Proc. of EMNLP , Jun 2014
We describe a new dependency parser for English tweets, TWEEBOPARSER. The parser builds on several contributions: new syntactic annotations for a corpus of tweets (TWEEBANK), with conventions informed by the domain; adaptations to a statistical parsing algorithm; and a new approach to exploiting out-of-domain Penn Treebank data. Our experiments show that the parser achieves over 80% unlabeled attachment accuracy on our new, high-quality test set and measure the benefit of our contributions.
- SemEvalSam Thomson , Brendan O’Connor , Jeffrey Flanigan , David Bamman , Jesse Dodge , Swabha Swayamdipta, Nathan Schneider , Chris Dyer , and Noah A. SmithIn Proc. of SemEval , Jun 2014
We present an arc-factored statistical model for semantic dependency parsing, as defined by the SemEval 2014 Shared Task 8 on Broad-Coverage Semantic Dependency Parsing. Our entry in the open track placed second in the competition.
- WMTAustin Matthews , Waleed Ammar , Archna Bhatia , Weston Feely , Greg Hanneman , Eva Schlinger , Swabha Swayamdipta, Yulia Tsvetkov , Alon Lavie , and 1 more authorIn Proc. of WMT , Jun 2014
We describe the CMU systems submitted to the 2014 WMT shared translation task. We participated in two language pairs, German–English and Hindi–English. Our innovations include: a label coarsening scheme for syntactic tree-to-tree translation, a host of new discriminative features, several modules to create “synthetic translation options” that can generalize beyond what is directly observed in the training data, and a method of combining the output of multiple word aligners to uncover extra phrase pairs and grammar rules.
2012
- ICSCSwabha Swayamdipta, and Owen RambowIn Proc. of ICSC , Jun 2012
In this paper we explore the written dialog behavior of participants in anon line discussion for automatic identification of participants who pursue power within the discussion group. We employ various standard unsupervised machine learning approaches to make this prediction. Our approach relies on the identification of certain discourse structures and linguistic techniques used by participants in the discussion. We achive an F-measure of 69.5% using unsupervised methods.