Swabha Swayamdipta
Gabilan Assistant Professor • USC Viterbi CS • Associate Director of USC Center for AI and Society • Amazon Scholar • USC NLP

My goal is to design frameworks that allow robust, and reliable frameworks that allow AI systems to be broadly and safely deployed, especially in applications with societal implications. Three directions that this corresponds to are:
-
- Safety-Critical, Robust and Reliable Language Models:
- What cannot be measured, cannot be improved. How can we reliably compare the generative capabilities of language models, and ensure our assessment is robust? How can we tell if performance match can translate to application safety, especially when there are societal implications? How can we evaluate new capabilities in LLMs when we do not necessarily know the correct answer?
-
- Understanding the Mechanisms that Drive Language Models:
- Even the most reliable evaluation may not reveal much about the mechanisms driving powerful yet opaque models. What do model geometries reveal about the processes underlying our models, and how can we improve models through different designs? Are models by design limited to making some choices which can uniquely identify them?
-
- Private and Safe Human-AI Collaboration for High-Stakes Applications:
- AI technologies are designed by humans and for humans, the future of AI involves cooperation and collaboration with humans. How can we say when a general-purpose model will reliably serve the custom utility for a human user? Where can these technologies complement human capabilities and where not?
These challenges require novel and creative techniques for redesigning generative evaluation to keep pace with model performance. This brings together a broad array of empirical research with theoretical fundamentals underlying language models.
news
| Jan 21, 2026 | Had my first podcast appearance for the Women in AI Research podcast, hosted by Jekaterina Novikova. |
|---|---|
| Dec 08, 2025 | Honored to receive an NIH AIM-Ahead Hub-Specific Project Award with Eric Rice on using AI for helping Youth Homelessness Serving Organizations. |
| Apr 25, 2025 | Honored to receive a sponsored research grant by Apple. |
| Apr 23, 2025 | DILL lab has newly minted entrepreneurs: Jaspreet Ranjit and Aryan Gulati are the Min Family Challenge winners in 2025. |
| Apr 23, 2025 | DILL Lab wins two awards at ShowCAIS 2025: best poster by undergrad Risha Surana and runner-up best oral presentation by Jaspreet Ranjit. |
selected publications
See here for a full list.- ICMLProc. of ICML, 2026
- ACL
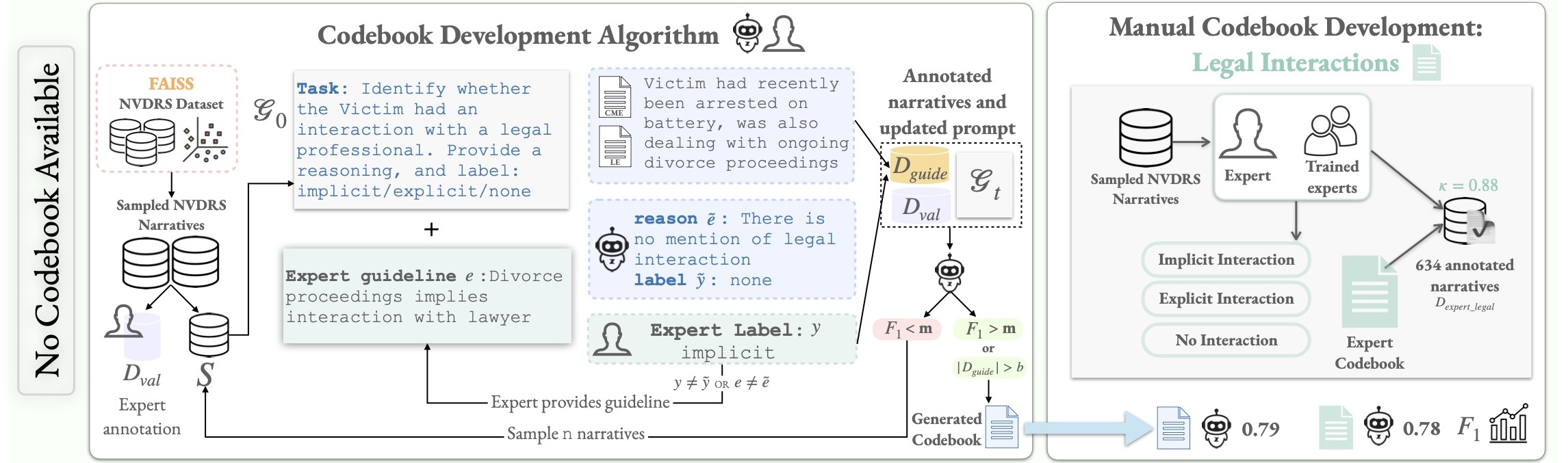 Proc. of ACL / NeurIPS Workshop on GenAI for Health / EAAMO, 2026
Proc. of ACL / NeurIPS Workshop on GenAI for Health / EAAMO, 2026 -
-
- NeurIPS
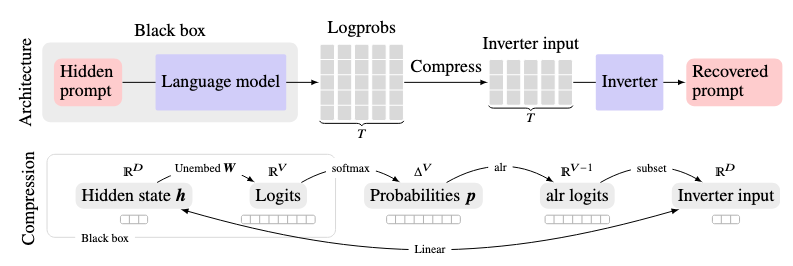 Proc. of NeurIPS, 2025
Proc. of NeurIPS, 2025 - CoLM
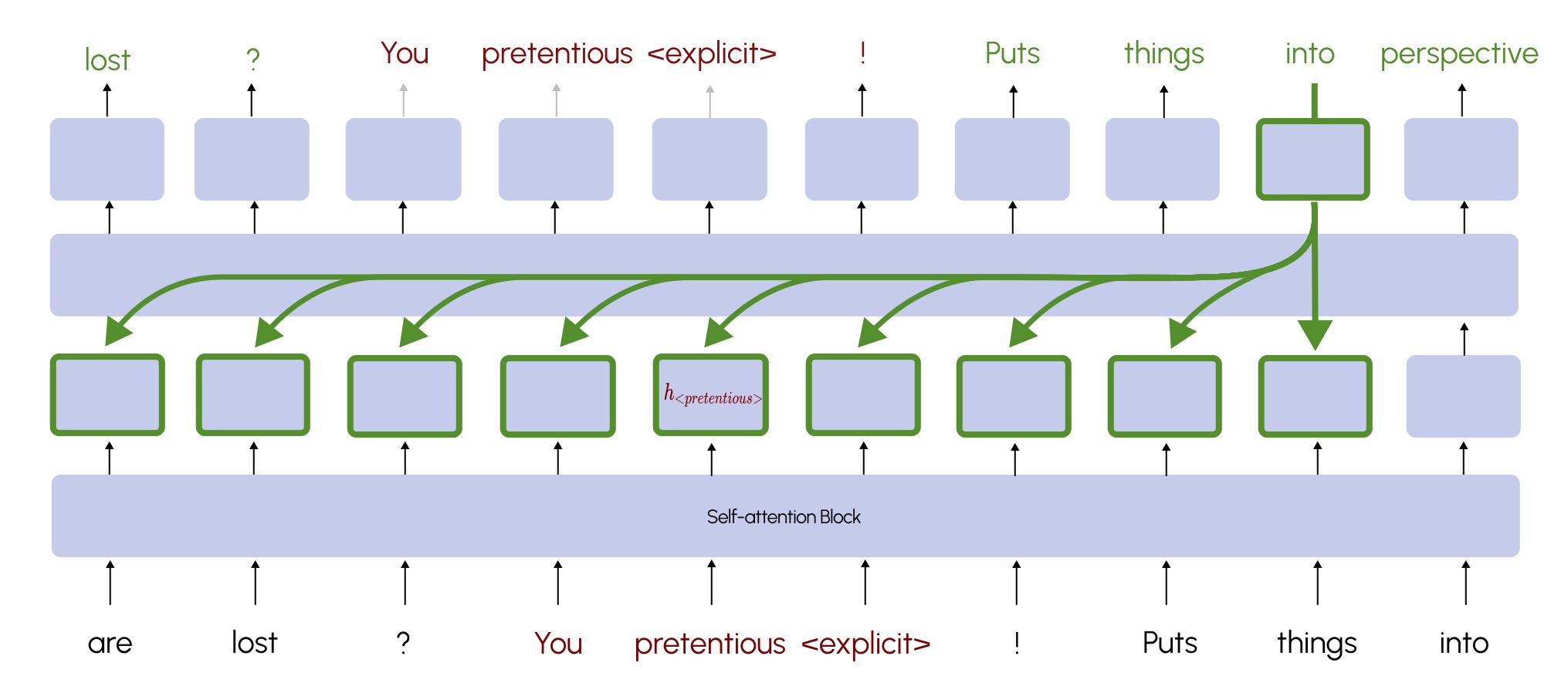 Conference on Language Modeling, 2025
Conference on Language Modeling, 2025 - ACL
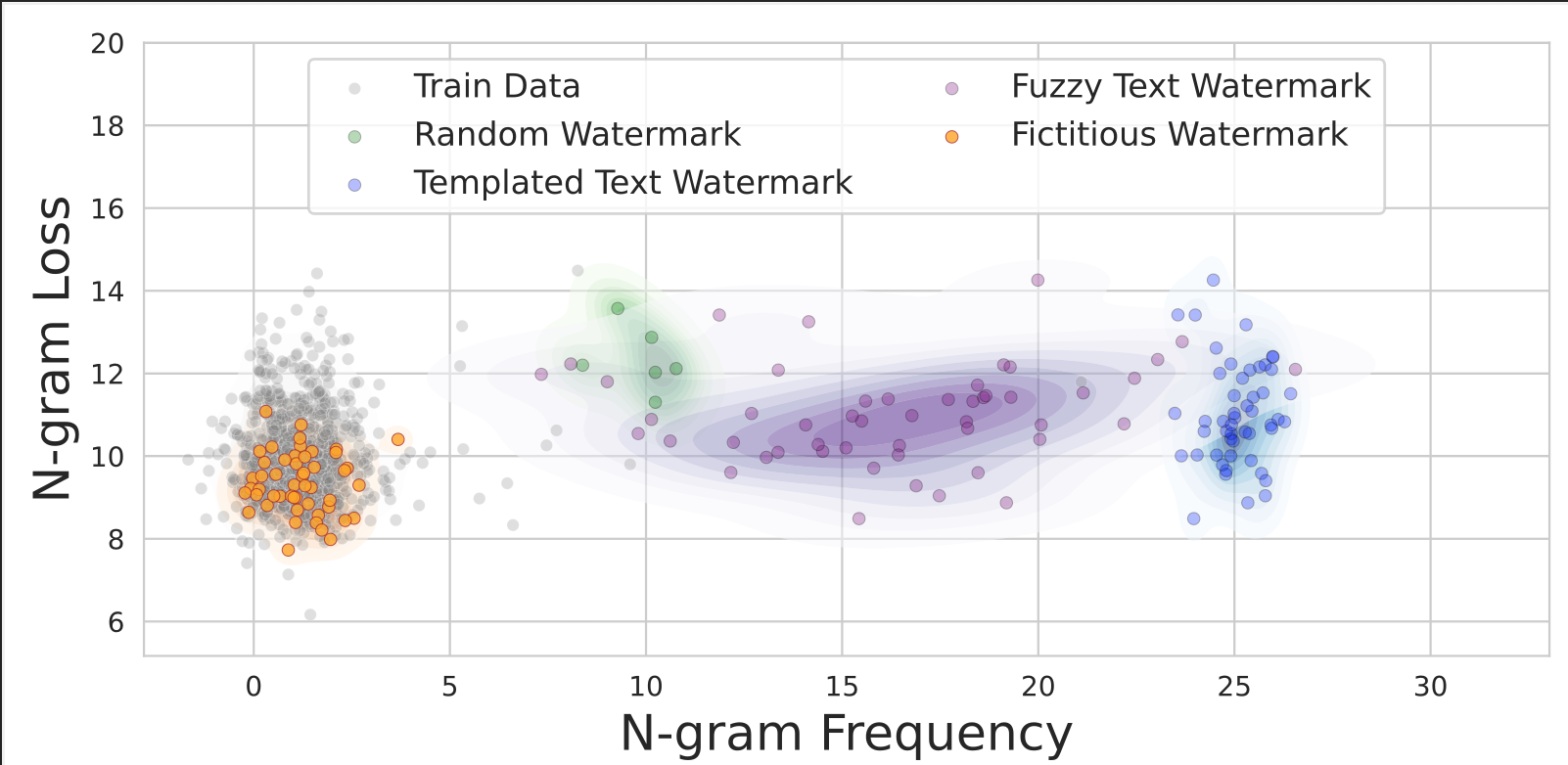 Findings of ACL, 2025
Findings of ACL, 2025 - ACL
- COLM
- ICML
 In Proc. of ICML , 2022
In Proc. of ICML , 2022 - NeurIPS
- EMNLP
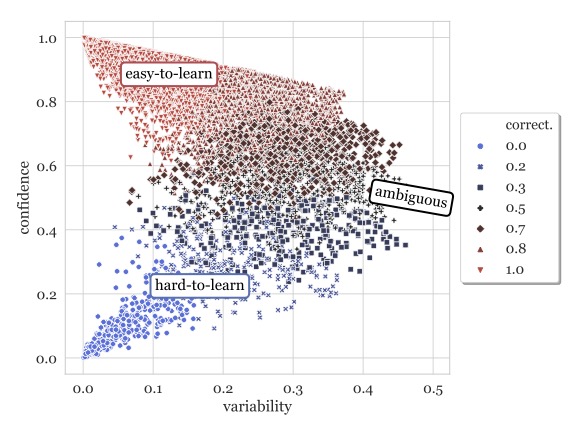 In Proc. of EMNLP , 2020
In Proc. of EMNLP , 2020 - ACL

- NAACL
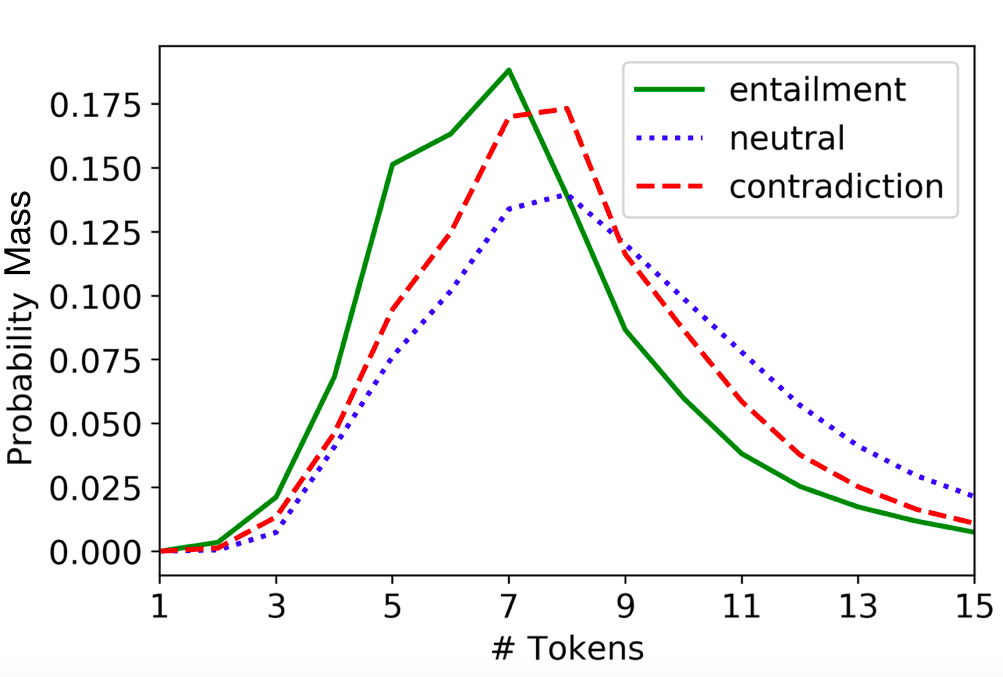 In Proc. of NAACL , 2018
In Proc. of NAACL , 2018













